So-ViT: Mind Visual Tokens for Vision Transformer
Introduction
This repository contains the source code under PyTorch framework and models trained on ImageNet-1K dataset for the following paper:
@articles{So-ViT,
author = {Jiangtao Xie, Ruiren Zeng, Qilong Wang, Ziqi Zhou, Peihua Li},
title = {So-ViT: Mind Visual Tokens for Vision Transformer},
booktitle = {arXiv:2104.10935},
year = {2021}
}
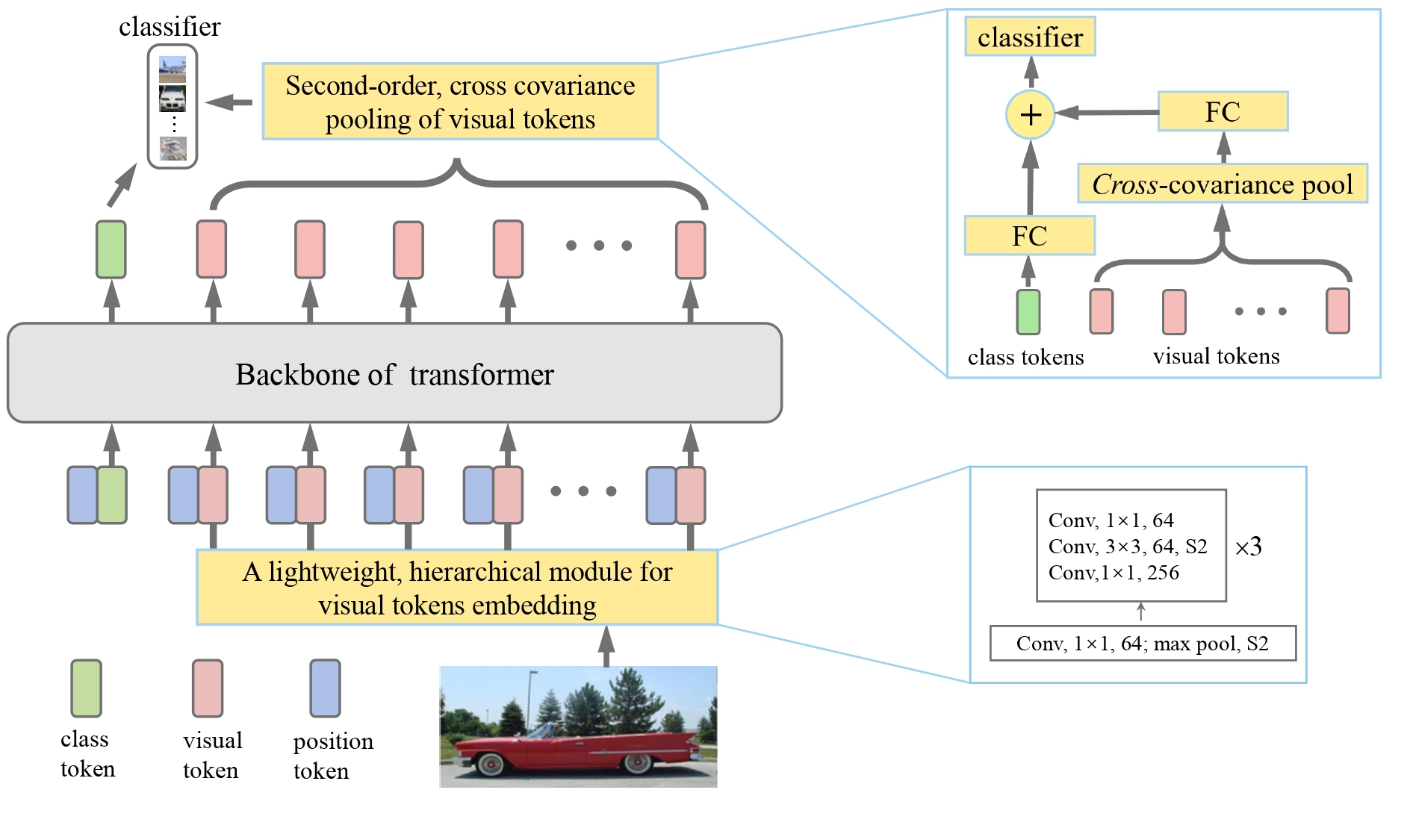
The Vision Transformer (ViT) heavily depends on pretraining using ultra large-scale datasets (e.g. ImageNet-21K or JFT-300M) to achieve high performance, while significantly underperforming on ImageNet-1K if trained from scratch. We propose a novel So-ViT model toward addressing this problem, by carefully considering the role of visual tokens.
Above all, for classification head, the ViT only exploits class token while entirely neglecting rich semantic information inherent in high-level visual tokens. Therefore, we propose a new classification paradigm, where the second-order, cross-covariance pooling of visual tokens is combined with class token for final classification. Meanwhile, a fast singular value power normalization is proposed for improving the second-order pooling.
Second, the ViT employs the naïve method of one linear projection of fixed-size image patches for visual token embedding, lacking the ability to model translation equivariance and locality. To alleviate this problem, we develop a light-weight, hierarchical module based on off-the-shelf convolutions for visual token embedding.
Classification results
Classification results (single crop 224x224, %) on ImageNet-1K validation set
| Network | Top-1 Accuracy | Pre-trained models | ||
|---|---|---|---|---|
| Paper reported | Upgrade | GoogleDrive | BaiduCloud | |
| So-ViT-7 | 76.2 | 76.8 | Coming soon | Coming soon |
| So-ViT-10 | 77.9 | 78.7 | Coming soon | Coming soon |
| So-ViT-14 | 81.8 | 82.3 | Coming soon | Coming soon |
| So-ViT-19 | 82.4 | 82.8 | Coming soon | Coming soon |
Installation and Usage
- Install PyTorch (
>=1.6.0) - Install timm (
==0.3.4) pip install thop- type
git clone https://github.com/jiangtaoxie/So-ViT - prepare the dataset as follows
.
├── train
│ ├── class1
│ │ ├── class1_001.jpg
│ │ ├── class1_002.jpg
| | └── ...
│ ├── class2
│ ├── class3
│ ├── ...
│ ├── ...
│ └── classN
└── val
├── class1
│ ├── class1_001.jpg
│ ├── class1_002.jpg
| └── ...
├── class2
├── class3
├── ...
├── ...
└── classN
for training from scracth
sh model_name.sh # model_name = {So_vit_7/10/14/19}
Acknowledgment
pytorch: https://github.com/pytorch/pytorch
timm: https://github.com/rwightman/pytorch-image-models
T2T-ViT: https://github.com/yitu-opensource/T2T-ViT
Contact
If you have any questions or suggestions, please contact me

 7 Dec 18, 2022
7 Dec 18, 2022
 78 Dec 02, 2022
78 Dec 02, 2022
 3 Nov 30, 2021
3 Nov 30, 2021
 83 Dec 21, 2022
83 Dec 21, 2022
 1 Jan 12, 2022
1 Jan 12, 2022
 231 Nov 15, 2022
231 Nov 15, 2022
 2 Jan 19, 2022
2 Jan 19, 2022
 35 Dec 29, 2022
35 Dec 29, 2022
 7 Oct 31, 2021
7 Oct 31, 2021
 28 Dec 09, 2022
28 Dec 09, 2022
 9 Dec 28, 2022
9 Dec 28, 2022
 34 Dec 08, 2022
34 Dec 08, 2022
 100 Dec 28, 2022
100 Dec 28, 2022
 121 Dec 28, 2022
121 Dec 28, 2022
 37 Oct 26, 2022
37 Oct 26, 2022
 50 Dec 16, 2022
50 Dec 16, 2022
 2 Feb 26, 2022
2 Feb 26, 2022
 554 Dec 30, 2022
554 Dec 30, 2022
 679 Jan 04, 2023
679 Jan 04, 2023
 21 Jul 30, 2022
21 Jul 30, 2022