Cartoon-StyleGAN
🙃
: Fine-tuning StyleGAN2 for Cartoon Face Generation
Abstract
Recent studies have shown remarkable success in the unsupervised image to image (I2I) translation. However, due to the imbalance in the data, learning joint distribution for various domains is still very challenging. Although existing models can generate realistic target images, it’s difficult to maintain the structure of the source image. In addition, training a generative model on large data in multiple domains requires a lot of time and computer resources. To address these limitations, I propose a novel image-to-image translation method that generates images of the target domain by finetuning a stylegan2 pretrained model. The stylegan2 model is suitable for unsupervised I2I translation on unbalanced datasets; it is highly stable, produces realistic images, and even learns properly from limited data when applied with simple fine-tuning techniques. Thus, in this project, I propose new methods to preserve the structure of the source images and generate realistic images in the target domain.

Inference Notebook
Arxiv
[NEW!] 2021.08.30 Streamlit Ver

1. Method
Baseline : StyleGAN2-ADA + FreezeD
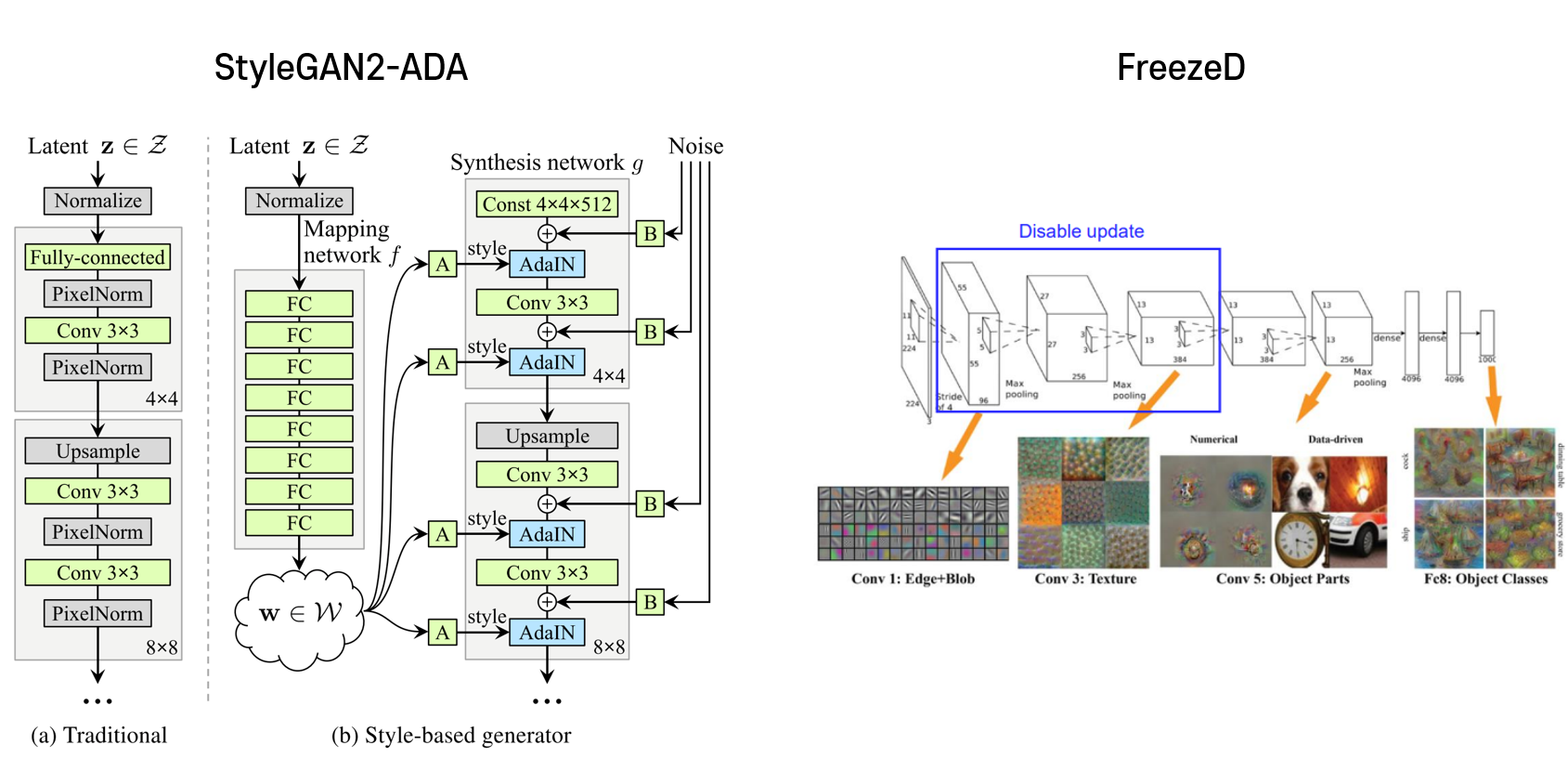
It generates realistic images, but does not maintain the structure of the source domain.
 |
 |
Ours : FreezeSG (Freeze Style vector and Generator)

FreezeG is effective in maintaining the structure of the source image. As a result of various experiments, I found that not only the initial layer of the generator but also the initial layer of the style vector are important for maintaining the structure. Thus, I froze the low-resolution layer of both the generator and the style vector.
Freeze Style vector and Generator

Results

With Layer Swapping
When LS is applied, the generated images by FreezeSG have a higher similarity to the source image than when FreezeG or the baseline (FreezeD + ADA) were used. However, since this fixes the weights of the low-resolution layer of the generator, it is difficult to obtain meaningful results when layer swapping on the low-resolution layer.

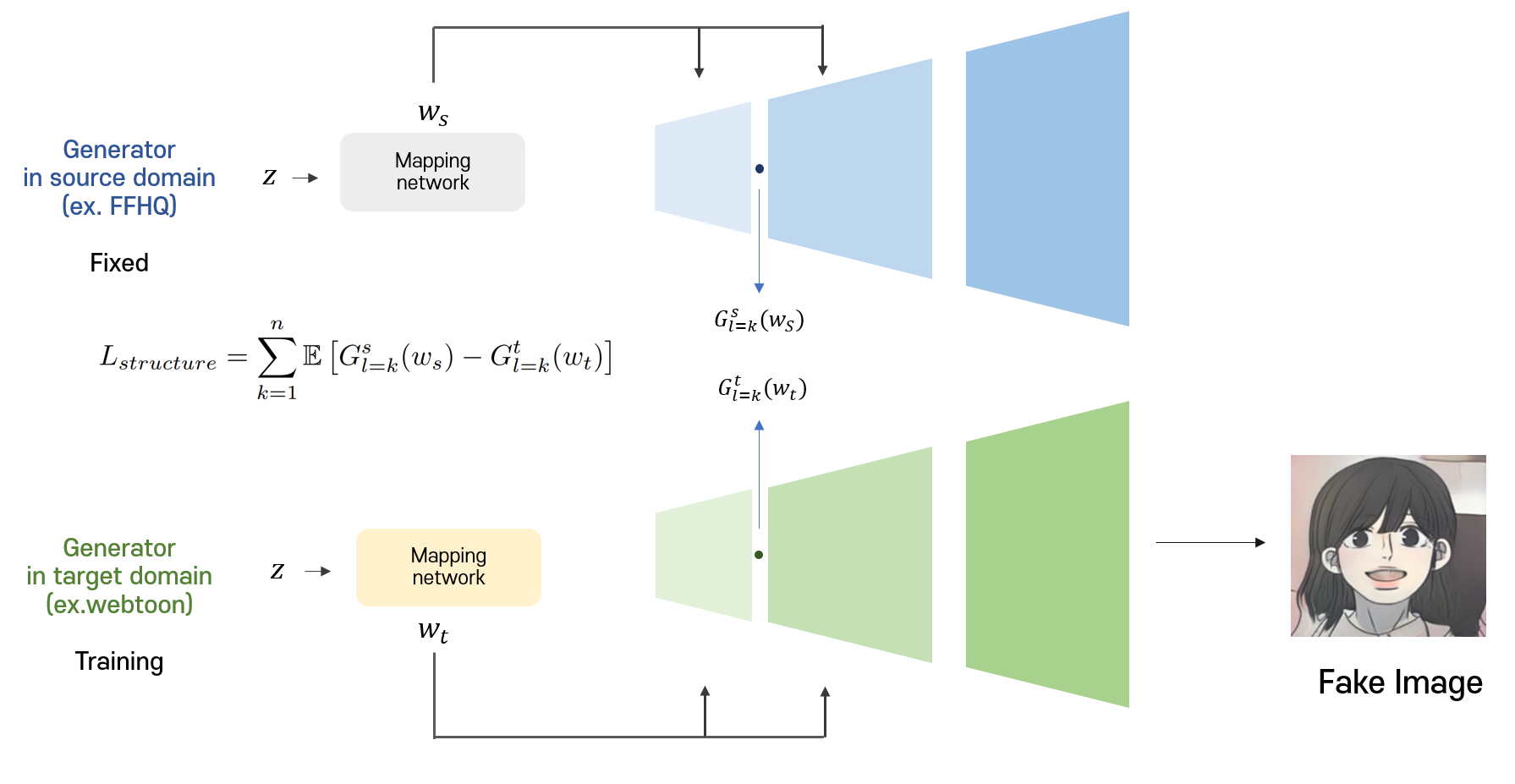
Ours : Structure Loss
Based on the fact that the structure of the image is determined at low resolution, I apply structure loss to the values of the low-resolution layer so that the generated image is similar to the image in the source domain. The structure loss makes the RGB output of the source generator to be fine-tuned to have a similar value with the RGB output of the target generator during training.

Results


Compare

2. Application : Change Facial Expression / Pose
I applied various models(ex. Indomain-GAN, SeFa, StyleCLIP…) to change facial expression, posture, style, etc.
(1) Closed Form Factorization(SeFa)
Pose

Slim Face

(2) StyleCLIP – Latent Optimization

Inspired by StyleCLIP that manipulates generated images with text, I change the faces of generated cartoon characters by text. I used the latent optimization method among the three methods of StyleCLIP and additionally introduced styleclip strength. It allows the latent vector to linearly move in the direction of the optimized latent vector, making the image change better with text.
with baseline model(FreezeD)


with our model(structureLoss)


(3) Style Mixing
Style-Mixing

When mixing layers, I found specifics layers that make a face. While the overall structure (hair style, facial shape, etc.) and texture (skin color and texture) were maintained, only the face(eyes, nose and mouth) was changed.


Results


3. Requirements
I have tested on:
- PyTorch 1.8.0, CUDA 11.1
- Docker :
pytorch/pytorch:1.8.0-cuda11.1-cudnn8-devel
Installation
Clone this repo :
git clone https://github.com/happy-jihye/Cartoon-StyleGan2
cd Cartoon-StyleGan2
Pretrained Models
Please download the pre-trained models from the following links.
| Path | Description |
|---|---|
| StyleGAN2-FFHQ256 | StyleGAN2 pretrained model(256px) with FFHQ dataset from Rosinality |
| StyleGAN2-Encoder | In-Domain GAN Inversion model with FFHQ dataset from Bryandlee |
| NaverWebtoon | FreezeD + ADA with NaverWebtoon Dataset |
| NaverWebtoon_FreezeSG | FreezeSG with NaverWebtoon Dataset |
| NaverWebtoon_StructureLoss | StructureLoss with NaverWebtoon Dataset |
| Romance101 | FreezeD + ADA with Romance101 Dataset |
| TrueBeauty | FreezeD + ADA with TrueBeauty Dataset |
| Disney | FreezeD + ADA with Disney Dataset |
| Disney_FreezeSG | FreezeSG with Disney Dataset |
| Disney_StructureLoss | StructureLoss with Disney Dataset |
| Metface_FreezeSG | FreezeSG with Metface Dataset |
| Metface_StructureLoss | StructureLoss with Metface Dataset |
If you want to download all of the pretrained model, you can use download_pretrained_model() function in utils.py.
Dataset
I experimented with a variety of datasets, including Naver Webtoon, Metfaces, and Disney.
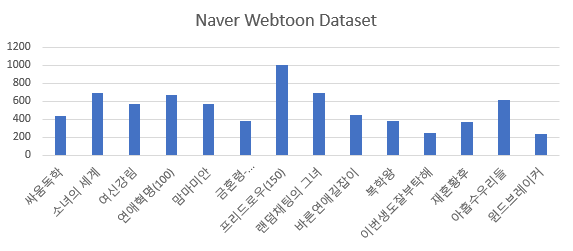
NaverWebtoon Dataset contains facial images of webtoon characters serialized on Naver. I made this dataset by crawling webtoons from Naver’s webtoons site and cropping the faces to 256 x 256 sizes. There are about 15 kinds of webtoons and 8,000 images(not aligned). I trained the entire Naver Webtoon dataset, and I also trained each webtoon in this experiment
I was also allowed to share a pretrained model with writers permission to use datasets. Thank you for the writers (Yaongyi, Namsoo, justinpinkney) who gave us permission.
Getting Started !
1. Prepare LMDB Dataset
First create lmdb datasets:
python prepare_data.py --out LMDB_PATH --n_worker N_WORKER --size SIZE1,SIZE2,SIZE3,... DATASET_PATH
# if you have zip file, change it to lmdb datasets by this commend
python run.py --prepare_data=DATASET_PATH --zip=ZIP_NAME --size SIZE
2. Train
# StyleGAN2
python train.py --batch BATCH_SIZE LMDB_PATH
# ex) python train.py --batch=8 --ckpt=ffhq256.pt --freezeG=4 --freezeD=3 --augment --path=LMDB_PATH
# StructureLoss
# ex) python train.py --batch=8 --ckpt=ffhq256.pt --structure_loss=2 --freezeD=3 --augment --path=LMDB_PATH
# FreezeSG
# ex) python train.py --batch=8 --ckpt=ffhq256.pt --freezeStyle=2 --freezeG=4 --freezeD=3 --augment --path=LMDB_PATH
# Distributed Settings
python train.py --batch BATCH_SIZE --path LMDB_PATH \
-m torch.distributed.launch --nproc_per_node=N_GPU --main_port=PORT
Options
-
Project images to latent spaces
python projector.py --ckpt [CHECKPOINT] --size [GENERATOR_OUTPUT_SIZE] FILE1 FILE2 ... -
You can use
closed_form_factorization.pyandapply_factor.pyto discover meaningful latent semantic factor or directions in unsupervised manner.First, you need to extract eigenvectors of weight matrices using
closed_form_factorization.pypython closed_form_factorization.py [CHECKPOINT]This will create factor file that contains eigenvectors. (Default: factor.pt) And you can use
apply_factor.pyto test the meaning of extracted directionspython apply_factor.py -i [INDEX_OF_EIGENVECTOR] -d [DEGREE_OF_MOVE] -n [NUMBER_OF_SAMPLES] --ckpt [CHECKPOINT] [FACTOR_FILE] # ex) python apply_factor.py -i 19 -d 5 -n 10 --ckpt [CHECKPOINT] factor.pt
StyleGAN2-ada + FreezeD
During the experiment, I also carried out a task to generate a cartoon image based on Nvidia Team's StyleGAN2-ada code. When training these models, I didn't control the dataset resolution(256px)
You can practice based on this code at Colab :
| Generated-Image | Interpolation |
|---|---|
 |
 |
 |
 |
 |
 |

 19 Nov 05, 2022
19 Nov 05, 2022
 72 Dec 09, 2022
72 Dec 09, 2022
 100 Dec 01, 2022
100 Dec 01, 2022
 35 Dec 30, 2022
35 Dec 30, 2022
 25 Dec 13, 2022
25 Dec 13, 2022
 49 Dec 22, 2022
49 Dec 22, 2022
 5 Nov 10, 2022
5 Nov 10, 2022
 1 Dec 10, 2021
1 Dec 10, 2021
 19 Dec 14, 2022
19 Dec 14, 2022
 441 Dec 20, 2022
441 Dec 20, 2022
 2 Oct 12, 2022
2 Oct 12, 2022
 10 Dec 08, 2022
10 Dec 08, 2022
 3 Aug 28, 2022
3 Aug 28, 2022
 51 Dec 08, 2022
51 Dec 08, 2022
 12 Nov 09, 2022
12 Nov 09, 2022
 2 Dec 08, 2022
2 Dec 08, 2022
 133 Dec 28, 2022
133 Dec 28, 2022
 6 Dec 13, 2022
6 Dec 13, 2022
 40 Dec 12, 2022
40 Dec 12, 2022
 30 Nov 22, 2022
30 Nov 22, 2022