Scriptfab - What is it?
A python script to prefab your scripts/text files, and re create them with ease and not have to open your browser to copy code or write code yourself. You can copy paste or write a script into the python file and re instance it easily. You don't have to wait for your browser to load, you don't have to re-watch a tutorial to write code. Example of practical use: You start a new Godot or Unity project and you need to write a Player script (player controller) and you need to look up the code or watch a tutorial, instead of doing that you can copy and paste that code into the python script once and re-instance it as many times you want in the future by running the python file.
Scriptfab - How to use it?
Download the python file and place it in your project folder, open it using a text editor (preferably Visual Studio Code/Sublime Text/Notepad++/Pycharm) then take a look at the comments, I have tried to explain as much as I can. I will also go through how to use it here.

Look at the variable called "script_content", this is where your script that you want to re-use goes. Start off by deleting "# Delete this comment and copy paste/write the script you want to re-use here" inside of the triple quotes.
Then copy/paste or write the script there, example: 
Now to configure the command Scroll down to find this, 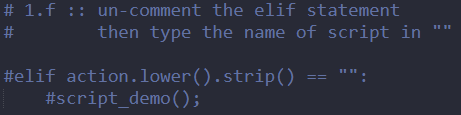 Then un-comment the elif statement. Write the name of command that you want to type when running the python file inside the ""
Then un-comment the elif statement. Write the name of command that you want to type when running the python file inside the "" 
 (MAKE SURE IT IS LOWERCASE)
(MAKE SURE IT IS LOWERCASE)
Scroll up to find this,  Then create a new list value as a string and add the name of the command you used
Then create a new list value as a string and add the name of the command you used 
To add more script prefabs, just re create a similar function and elif statement.
Scriptfab - End result/Running the py file
Requirements: Python Go to where you have the python file using file explorer. 
Right click on dead space while holding your Shift key. 
Then simply click 'Open PowerShell window here' (This could say CommandPrompt for you depending on your windows version). After you see the powershell window. 
Type in 
You should see this. 
Type in 'scripts' to see the list of scripts you added. 
Then type in the command you defined before. 
Then type the filename and file extentsion. 
Check again in the folder to see the script you defined before magically appeared! 
Enjoy saving time!
Permission to change the script
Do what ever you want with it :D

 1.2k Dec 30, 2022
1.2k Dec 30, 2022
 137 Dec 18, 2022
137 Dec 18, 2022
 213 Jan 04, 2023
213 Jan 04, 2023
 1 Jan 05, 2022
1 Jan 05, 2022
 237 Nov 04, 2022
237 Nov 04, 2022
 1 Jan 18, 2022
1 Jan 18, 2022
 14 Mar 25, 2022
14 Mar 25, 2022
 312 Jan 03, 2023
312 Jan 03, 2023
 1 Oct 29, 2021
1 Oct 29, 2021
 48 Nov 15, 2022
48 Nov 15, 2022
 60 Dec 12, 2022
60 Dec 12, 2022
 1 Oct 28, 2021
1 Oct 28, 2021
 4 Nov 06, 2022
4 Nov 06, 2022
 9.1k Jan 02, 2023
9.1k Jan 02, 2023
 1.8k Dec 27, 2022
1.8k Dec 27, 2022
 620 Dec 29, 2022
620 Dec 29, 2022
 1 Jan 18, 2022
1 Jan 18, 2022
 730 Jan 09, 2023
730 Jan 09, 2023
 12 Sep 28, 2022
12 Sep 28, 2022
 2.7k Jan 08, 2023
2.7k Jan 08, 2023