Unsupervised State Representation Learning in Atari
Ankesh Anand*, Evan Racah*, Sherjil Ozair*, Yoshua Bengio, Marc-Alexandre Côté, R Devon Hjelm
This repo provides code for the benchmark and techniques introduced in the paper Unsupervised State Representation Learning in Atari
-
📦 Install -- Install relevant dependencies and the project -
🔧 Usage -- Learn how to use AtariARI and train representations with Spatio-Temporal DeepInfomax (ST-DIM) -
🕹️ RAM Annotations -- Mapping of RAM indexes to semantic state variables -
📜 Poster -- Summary of the paper in a poster format -
🎞️ Slides -- Slides describing the paper
Install
AtariARI Wrapper
You can do a minimal install to get just the AtariARI (Atari Annotated RAM Interface) wrapper by doing:
pip install 'gym[atari]'
pip install git+git://github.com/mila-iqia/atari-representation-learning.git
This just requires gym[atari] and it gives you the ability to play around with the AtariARI wrapper. If you want to use the code for training representation learning methods and probing them, you will need a full installation:
Full installation (AtariARI Wrapper + Training & Probing Code)
# PyTorch and scikit learn
conda install pytorch torchvision -c pytorch
conda install scikit-learn
# Baselines for Atari preprocessing
# Tensorflow is a dependency, but you don't need to install the GPU version
conda install tensorflow
pip install git+git://github.com/openai/baselines
# pytorch-a2c-ppo-acktr for RL utils
pip install git+git://github.com/ankeshanand/pytorch-a2c-ppo-acktr-gail
# Clone and install our package
pip install -r requirements.txt
pip install git+git://github.com/mila-iqia/atari-representation-learning.git
Usage
Atari Annotated RAM Interface (AtariARI):
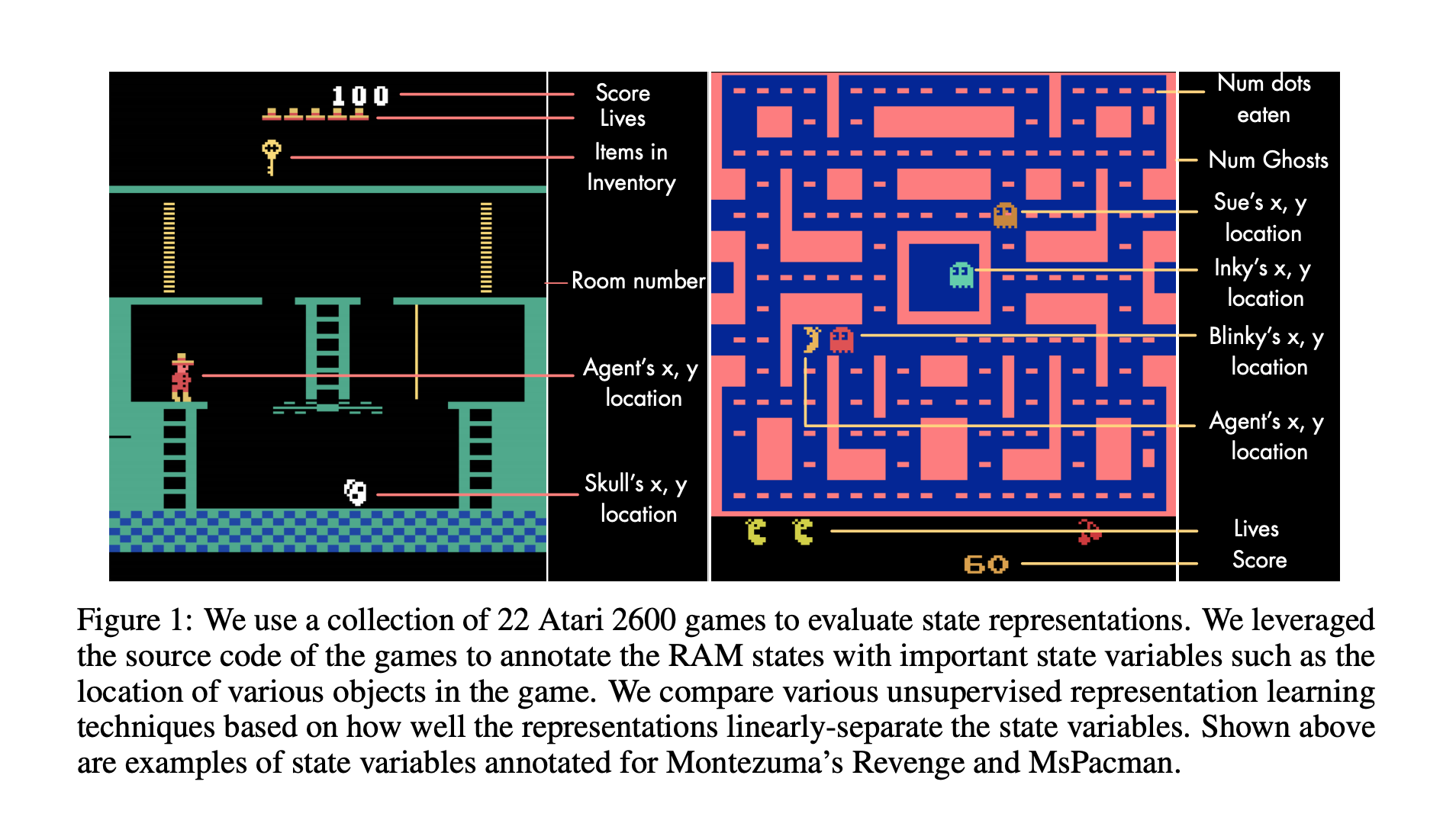
AtariARI exposes the ground truth labels for different state variables for each observation. We have made AtariARI available as a Gym wrapper, to use it simply wrap an Atari gym env with AtariARIWrapper.
import gym
from atariari.benchmark.wrapper import AtariARIWrapper
env = AtariARIWrapper(gym.make('MsPacmanNoFrameskip-v4'))
obs = env.reset()
obs, reward, done, info = env.step(1)
Now, info is a dictionary of the form:
{'ale.lives': 3,
'labels': {'enemy_sue_x': 88,
'enemy_inky_x': 88,
'enemy_pinky_x': 88,
'enemy_blinky_x': 88,
'enemy_sue_y': 80,
'enemy_inky_y': 80,
'enemy_pinky_y': 80,
'enemy_blinky_y': 50,
'player_x': 88,
'player_y': 98,
'fruit_x': 0,
'fruit_y': 0,
'ghosts_count': 3,
'player_direction': 3,
'dots_eaten_count': 0,
'player_score': 0,
'num_lives': 2}}
Note: In our experiments, we use additional preprocessing for Atari environments mainly following Minh et. al, 2014. See atariari/benchmark/envs.py for more info!
If you want the raw RAM annotations (which parts of ram correspond to each state variable), check out atariari/benchmark/ram_annotations.py
Probing
We provide an interface for the included probing tasks.
First, get episodes for train, val and, test:
from atariari.benchmark.episodes import get_episodes
tr_episodes, val_episodes,\
tr_labels, val_labels,\
test_episodes, test_labels = get_episodes(env_name="PitfallNoFrameskip-v4",
steps=50000,
collect_mode="random_agent")
Then probe them using ProbeTrainer and your encoder (my_encoder):
from atariari.benchmark.probe import ProbeTrainer
probe_trainer = ProbeTrainer(my_encoder, representation_len=my_encoder.feature_size)
probe_trainer.train(tr_episodes, val_episodes,
tr_labels, val_labels,)
final_accuracies, final_f1_scores = probe_trainer.test(test_episodes, test_labels)
To see how we use ProbeTrainer, check out scripts/run_probe.py
Here is an example of my_encoder:
# get your encoder
import torch.nn as nn
import torch
class MyEncoder(nn.Module):
def __init__(self, input_channels, feature_size):
super().__init__()
self.feature_size = feature_size
self.input_channels = input_channels
self.final_conv_size = 64 * 9 * 6
self.cnn = nn.Sequential(
nn.Conv2d(input_channels, 32, 8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, 4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 128, 4, stride=2),
nn.ReLU(),
nn.Conv2d(128, 64, 3, stride=1),
nn.ReLU()
)
self.fc = nn.Linear(self.final_conv_size, self.feature_size)
def forward(self, inputs):
x = self.cnn(inputs)
x = x.view(x.size(0), -1)
return self.fc(x)
my_encoder = MyEncoder(input_channels=1,feature_size=256)
# load in weights
my_encoder.load_state_dict(torch.load(open("path/to/my/weights.pt", "rb")))
Spatio-Temporal DeepInfoMax:
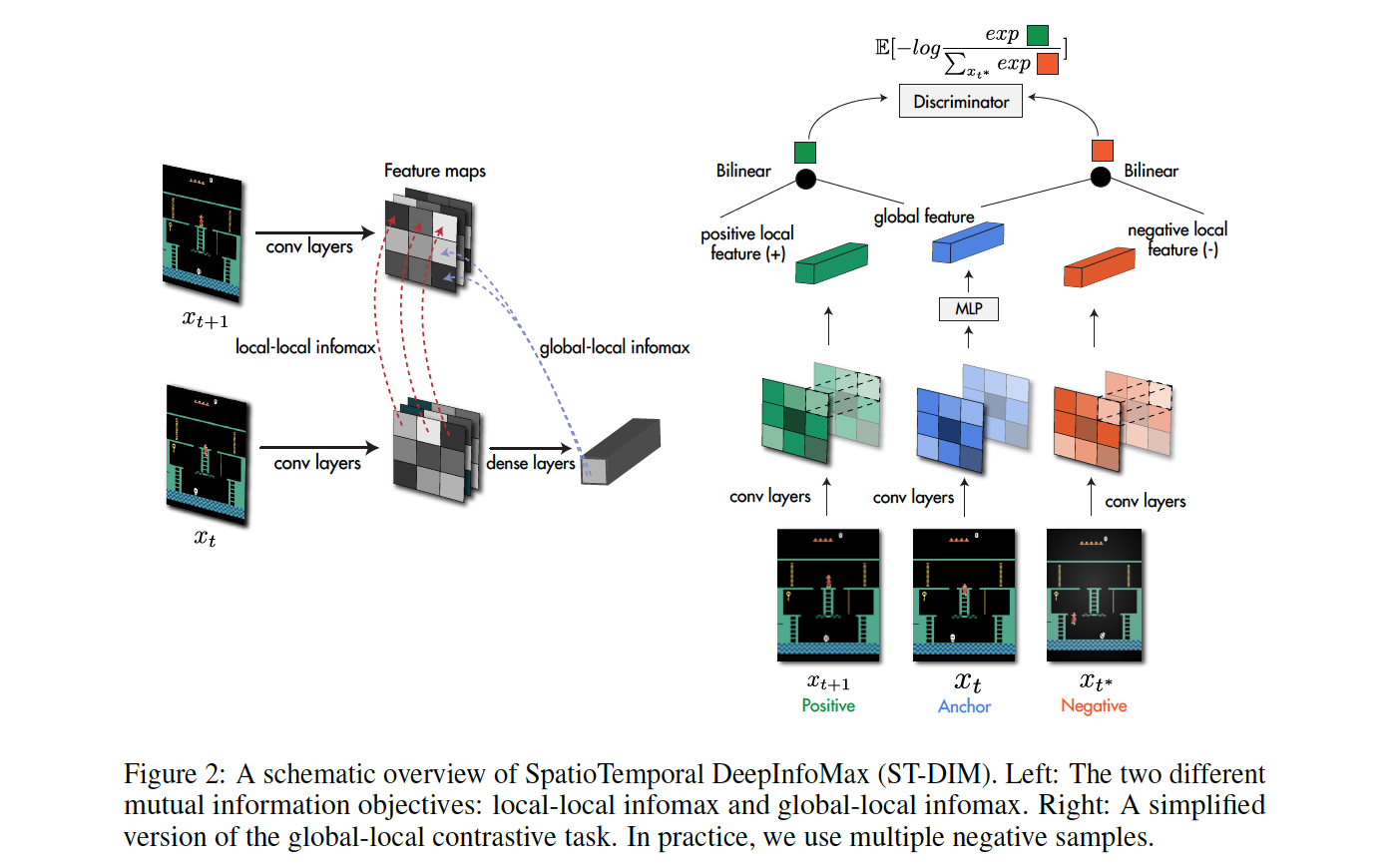
src/ contains implementations of several representation learning methods, along with ST-DIM. Here's a sample usage:
python -m scripts.run_probe --method infonce-stdim --env-name {env_name}
where env_name is of the form {game}NoFrameskip-v4, such as PongNoFrameskip-v4
Citation
@article{anand2019unsupervised,
title={Unsupervised State Representation Learning in Atari},
author={Anand, Ankesh and Racah, Evan and Ozair, Sherjil and Bengio, Yoshua and C{\^o}t{\'e}, Marc-Alexandre and Hjelm, R Devon},
journal={arXiv preprint arXiv:1906.08226},
year={2019}
}

 272 Dec 23, 2022
272 Dec 23, 2022
 11 Dec 09, 2022
11 Dec 09, 2022
 100 Dec 19, 2022
100 Dec 19, 2022
 27 Nov 23, 2022
27 Nov 23, 2022
 2 Apr 12, 2022
2 Apr 12, 2022
 8.3k Dec 31, 2022
8.3k Dec 31, 2022
 123 Dec 28, 2022
123 Dec 28, 2022
 15 Apr 16, 2022
15 Apr 16, 2022
 43 Nov 25, 2022
43 Nov 25, 2022
 1.5k Jan 02, 2023
1.5k Jan 02, 2023
 1.5k Jan 08, 2023
1.5k Jan 08, 2023
 175 Feb 18, 2022
175 Feb 18, 2022
 48 Sep 27, 2022
48 Sep 27, 2022
 [email protected])">
190 Dec 11, 2022
[email protected])">
190 Dec 11, 2022
 489 Jan 07, 2023
489 Jan 07, 2023
 377 Jan 05, 2023
377 Jan 05, 2023
 12 Jul 08, 2022
12 Jul 08, 2022
 11 Nov 17, 2022
11 Nov 17, 2022
 579 Dec 22, 2022
579 Dec 22, 2022
 2.7k Jan 05, 2023
2.7k Jan 05, 2023