Common Sense Beyond English: Evaluating and Improving Multilingual LMs for Commonsense Reasoning
This is the Github repository of our paper, "Common Sense Beyond English: Evaluating and Improving Multilingual Language Models for Commonsense Reasoning" (in Proc. of ACL2021) about MickeyProbe and X-CSR. The detailed information and the links to download our data are available on the project website: https://inklab.usc.edu/XCSR/.
Code
Herein, we show the code and scripts for running the MickeyProbe experiments (mickey_probe), X-CSR experiments (xcsr_experiments) and the proposed multilingual contrastive pre-training method (mcp_generation). Ther are instructions under each folder and please refer to our paper if you would like to know more details.
Paper Abstract
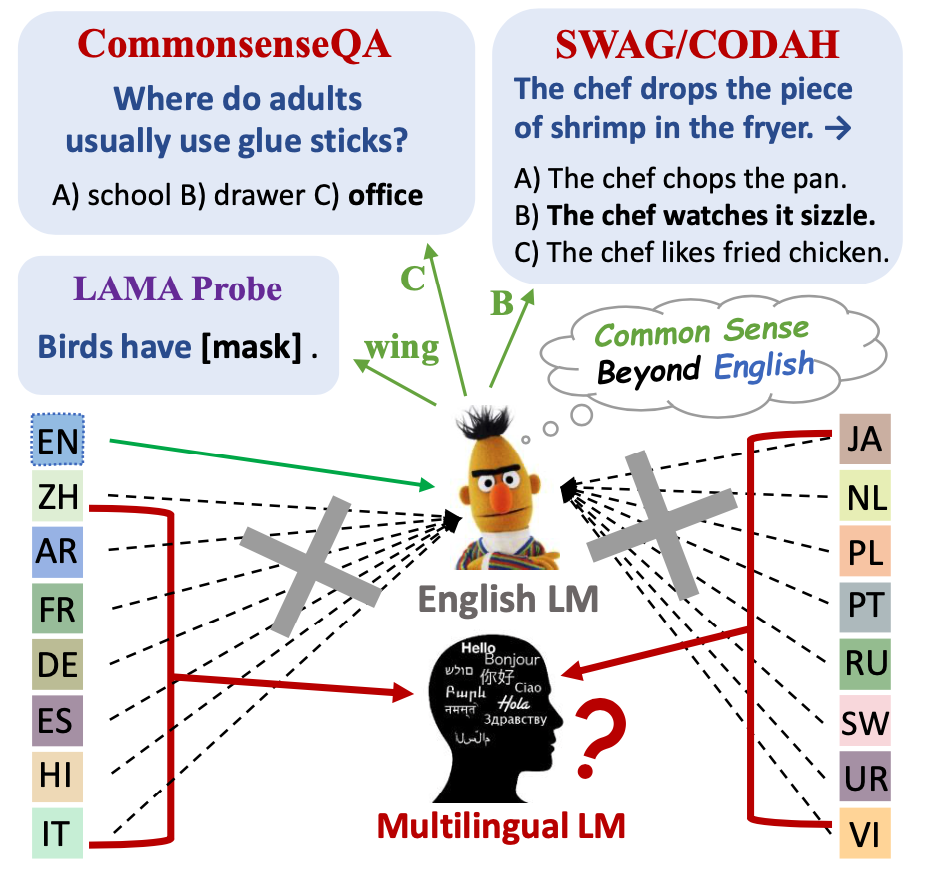
Commonsense reasoning research has so far been mainly limited to English. We aim to evaluate and improve popular multilingual language models (ML-LMs) to help advance commonsense reasoning (CSR) beyond English. We collect the Mickey Corpus, consisting of 561k sentences in 11 different languages, which can be used for analyzing and improving ML-LMs. We propose Mickey Probe, a language-agnostic probing task for fairly evaluating the common sense of popular ML-LMs across different languages. In addition, we also create two new datasets, X-CSQA and X-CODAH, by translating their English versions to 15 other languages, so that we can evaluate popular ML-LMs for cross-lingual commonsense reasoning. To improve the performance beyond English, we propose a simple yet effective method --- multilingual contrastive pre-training (MCP). It significantly enhances sentence representations, yielding a large performance gain on both benchmarks.
Resources
We provide our resources and method for studying cross-lingual commonsense reasoning.
- A multi-lingual corpus for MickeyProbe task towards analyzing and pre-training ML-LMs.
- Two X-CSR datasets (i.e., X-CSQA and X-CODAH) for evaluation.
- The multilingual contrastive pre-training (MCP) method for improving ML-LMs' performance.
We also build X-CSR leaderboard so that people can compare their cross-lingual/multilingual models with each other in a unified evaluation protocol.
Citation
@inproceedings{lin-etal-2021-xcsr,
title = "Common Sense Beyond English: Evaluating and Improving Multilingual Language Models for Commonsense Reasoning",
author = "Lin, Bill Yuchen and Lee, Seyeon and Qiao, Xiaoyang and Ren, Xiang",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL-IJCNLP 2021)",
year = "2021",
note={to appear}
}
Contact
This repo is now under active development, and there may be issues caused by refactoring code. Please email [email protected] if you have any questions.

 216 Dec 29, 2022
216 Dec 29, 2022
 46 Dec 26, 2022
46 Dec 26, 2022
 65 Dec 27, 2022
65 Dec 27, 2022
 13 Nov 04, 2022
13 Nov 04, 2022
 182 Sep 06, 2021
182 Sep 06, 2021
 13 Oct 14, 2022
13 Oct 14, 2022
 559 Jan 01, 2023
559 Jan 01, 2023
 14 Jun 29, 2022
14 Jun 29, 2022
 3.8k Dec 29, 2022
3.8k Dec 29, 2022
 2 Apr 24, 2022
2 Apr 24, 2022
 47 Dec 27, 2022
47 Dec 27, 2022
 19 Nov 28, 2022
19 Nov 28, 2022
 36 Sep 20, 2022
36 Sep 20, 2022
 9 May 22, 2022
9 May 22, 2022
 16 Oct 10, 2022
16 Oct 10, 2022
 677 Dec 28, 2022
677 Dec 28, 2022
 17 Dec 30, 2022
17 Dec 30, 2022
 54 Jan 06, 2023
54 Jan 06, 2023
 7 Sep 20, 2022
7 Sep 20, 2022
 1.5k Jan 05, 2023
1.5k Jan 05, 2023