The COCO-Stuff dataset
Holger Caesar, Jasper Uijlings, Vittorio Ferrari

Overview
- Highlights
- Research Paper
- Versions of COCO-Stuff
- Downloads
- Setup
- Results
- Labels
- Semantic Segmentation Models
- Annotation Tool
- Misc
Highlights
- 164K complex images from COCO [2]
- Dense pixel-level annotations
- 80 thing classes, 91 stuff classes and 1 class 'unlabeled'
- Instance-level annotations for things from COCO [2]
- Complex spatial context between stuff and things
- 5 captions per image from COCO [2]
Research Paper
COCO-Stuff: Thing and Stuff Classes in Context
H. Caesar, J. Uijlings, V. Ferrari,
In Computer Vision and Pattern Recognition (CVPR), 2018.
[paper][bibtex]
Versions of COCO-Stuff
- COCO-Stuff dataset: The final version of COCO-Stuff, that is presented on this page. It includes all 164K images from COCO 2017 (train 118K, val 5K, test-dev 20K, test-challenge 20K). It covers 172 classes: 80 thing classes, 91 stuff classes and 1 class 'unlabeled'. This dataset will form the basis of all upcoming challenges.
- COCO 2017 Stuff Segmentation Challenge: A semantic segmentation challenge on 55K images (train 40K, val 5K, test-dev 5K, test-challenge 5K) of COCO. To focus on stuff, we merged all 80 thing classes into a single class 'other'. The results of the challenge were presented at the Joint COCO and Places Recognition Workshop at ICCV 2017.
- COCO-Stuff 10K dataset: Our first dataset, annotated by 10 in-house annotators at the University of Edinburgh. It includes 10K images from the training set of COCO. We provide a 9K/1K (train/val) split to make results comparable. The dataset includes 80 thing classes, 91 stuff classes and 1 class 'unlabeled'. This was initially presented as 91 thing classes, but is now changed to 80 thing classes, as 11 classes do not have any segmentation annotations in COCO. This dataset is a subset of all other releases.
Downloads
| Filename | Description | Size |
|---|---|---|
| train2017.zip | COCO 2017 train images (118K images) | 18 GB |
| val2017.zip | COCO 2017 val images (5K images) | 1 GB |
| stuffthingmaps_trainval2017.zip | Stuff+thing PNG-style annotations on COCO 2017 trainval | 659 MB |
| stuff_trainval2017.zip | Stuff-only COCO-style annotations on COCO 2017 trainval | 543 MB |
| annotations_trainval2017.zip | Thing-only COCO-style annotations on COCO 2017 trainval | 241 MB |
| labels.md | Indices, names, previews and descriptions of the classes in COCO-Stuff | <10 KB |
| labels.txt | Machine readable version of the label list | <10 KB |
| README.md | This readme | <10 KB |
To use this dataset you will need to download the images (18+1 GB!) and annotations of the trainval sets. To download earlier versions of this dataset, please visit the COCO 2017 Stuff Segmentation Challenge or COCO-Stuff 10K.
Caffe-compatible stuff-thing maps We suggest using the stuffthingmaps, as they provide all stuff and thing labels in a single .png file per image. Note that the .png files are indexed images, which means they store only the label indices and are typically displayed as grayscale images. To be compatible with most Caffe-based semantic segmentation methods, thing+stuff labels cover indices 0-181 and 255 indicates the 'unlabeled' or void class.
Separate stuff and thing downloads Alternatively you can download the separate files for stuff and thing annotations in COCO format, which are compatible with the COCO-Stuff API. Note that the stuff annotations contain a class 'other' with index 183 that covers all non-stuff pixels.
Setup
Use the following instructions to download the COCO-Stuff dataset and setup the folder structure. The instructions are for Ubuntu and require git, wget and unzip. On other operating systems the commands may differ:
# Get this repo
git clone https://github.com/nightrome/cocostuff.git
cd cocostuff
# Download everything
wget --directory-prefix=downloads http://images.cocodataset.org/zips/train2017.zip
wget --directory-prefix=downloads http://images.cocodataset.org/zips/val2017.zip
wget --directory-prefix=downloads http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip
# Unpack everything
mkdir -p dataset/images
mkdir -p dataset/annotations
unzip downloads/train2017.zip -d dataset/images/
unzip downloads/val2017.zip -d dataset/images/
unzip downloads/stuffthingmaps_trainval2017.zip -d dataset/annotations/
Results
Below we present results on different releases of COCO-Stuff. If you would like to see your results here, please contact the first author.
Results on the val set of COCO-Stuff:
| Method | Source | Class accuracy | Pixel accuracy | Mean IOU | FW IOU |
|---|---|---|---|---|---|
| Deeplab VGG-16 (no CRF) [4] | [1] | 45.1% | 63.6% | 33.2% | 47.6% |
Note that the results between the 10K dataset and the full dataset are not direclty comparable, as different train and val images are used. Furthermore, on the full dataset we train Deeplab for 100K iterations [1], compared to 20K iterations on the 10K dataset [1b].
Results on the val set of the COCO 2017 Stuff Segmentation Challenge:
We show results on the val set of the challenge. Please refer to the official leaderboard for results on the test-dev and test-challenge sets. Note that these results are not comparable to other COCO-Stuff results, as the challenge only includes a single thing class 'other'.
| Method | Source | Class accuracy | Pixel accuracy | Mean IOU | FW IOU |
|---|---|---|---|---|---|
| Inplace-ABN sync | [8] | - | - | 24.9% | - |
Results on the val set of COCO-Stuff 10K:
| Method | Source | Class accuracy | Pixel accuracy | Mean IOU | FW IOU |
|---|---|---|---|---|---|
| FCN-16s [3] | [1b] | 34.0% | 52.0% | 22.7% | - |
| Deeplab VGG-16 (no CRF) [4] | [1b] | 38.1% | 57.8% | 26.9% | - |
| FCN-8s [3] | [6] | 38.5% | 60.4% | 27.2% | - |
| SCA VGG-16 [7] | [7] | 42.5% | 61.6% | 29.1% | - |
| DAG-RNN + CRF [6] | [6] | 42.8% | 63.0% | 31.2% | - |
| DC + FCN+ [5] | [5] | 44.6% | 65.5% | 33.6% | 50.6% |
| Deeplab ResNet (no CRF) [4] | - | 45.5% | 65.1% | 34.4% | 50.4% |
| CCL ResNet-101 [10] | [10] | 48.8% | 66.3% | 35.7% | - |
| DSSPN ResNet finetune [9] | [9] | 48.1% | 69.4% | 37.3% | - |
| * OHE + DC + FCN+ [5] | [5] | 45.8% | 66.6% | 34.3% | 51.2% |
| * W2V + DC + FCN+ [5] | [5] | 45.1% | 66.1% | 34.7% | 51.0% |
| * DSSPN ResNet universal [9] | [9] | 50.3% | 70.7% | 38.9% | - |
* Results not comparable as they use external data
Labels
Label Names & Indices
To be compatible with COCO, COCO-Stuff has 91 thing classes (1-91), 91 stuff classes (92-182) and 1 class "unlabeled" (0). Note that 11 of the thing classes of COCO do not have any segmentation annotations (blender, desk, door, eye glasses, hair brush, hat, mirror, plate, shoe, street sign, window). The classes desk, door, mirror and window could be either stuff or things and therefore occur in both COCO and COCO-Stuff. To avoid confusion we add the suffix "-stuff" or "-other" to those classes in COCO-Stuff. The full list of classes and their descriptions can be found here.
Label Hierarchy
This figure shows the label hierarchy of COCO-Stuff including all stuff and thing classes: 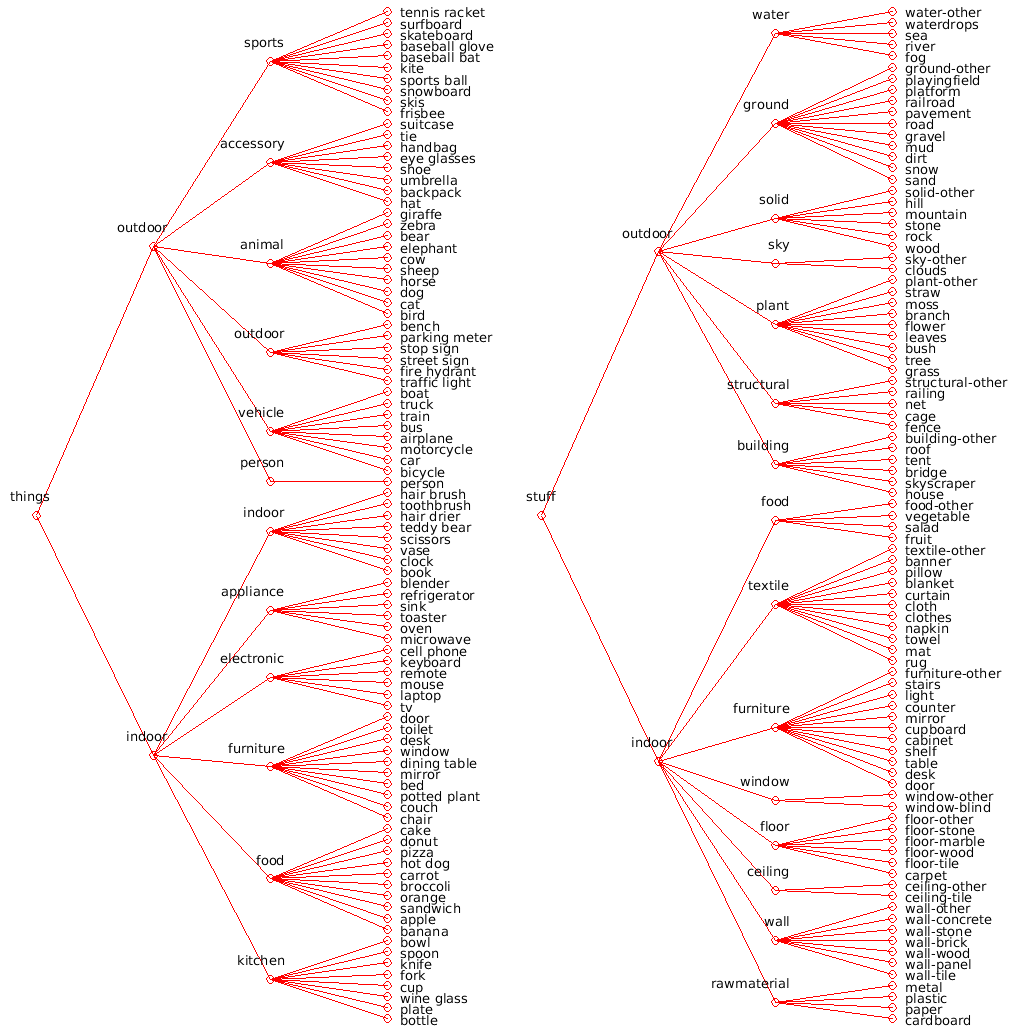
Semantic Segmentation Models (stuff+things)
PyTorch model
We recommend this third party re-implementation of Deeplab v2 in PyTorch. Contrary to our Caffe model, it supports ResNet and CRFs. The authors provide setup routines and models for COCO-Stuff 164K. Please file any issues or questions on the project's GitHub page.
Caffe model
Here we provide the Caffe-based segmentation model used in the COCO-Stuff paper. However, for users not familiar with Caffe we recommend the above PyTorch model. Before using the semantic segmentation model, please setup the dataset. The commands below download and install Deeplab (incl. Caffe), download or train the model and predictions and evaluate the performance. The results should be the same as in the table. Due to several issues, we do not provide the Deeplab ResNet101 model, but some code for it can be found in this folder.
# Get and install Deeplab (you may need to change settings)
# We use a special version of Deeplab v2 that supports CuDNN v5, but others may work as well.
git submodule update --init models/deeplab/deeplab-v2
cd models/deeplab/deeplab-v2
cp Makefile.config.example Makefile.config
make all -j8
# Create symbolic links to the images and annotations
cd models/deeplab/cocostuff/data && ln -s ../../../../dataset/images images && ln -s ../../../../dataset/annotations annotations && cd ../../../..
# Option 1: Download the initial model
# wget --directory-prefix=models/deeplab/cocostuff/model/deeplabv2_vgg16 http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/deeplabv2_vgg16_init.caffemodel
# Option 2: Download the trained model
# wg --directory-prefix=downloads http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/deeplab_cocostuff_trainedmodel.zip
# zip downloads/deeplab_cocostuff_trainedmodel.zip -d models/deeplab/cocostuff/model/deeplabv2_vgg16/model120kimages/
# Option 3: Run training & test
# cd models/deeplab && ./run_cocostuff_vgg16.sh && cd ../..
# Option 4 (fastest): Download predictions
wget --directory-prefix=downloads http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/deeplab_predictions_cocostuff_val2017.zip
unzip downloads/deeplab_predictions_cocostuff_val2017.zip -d models/deeplab/cocostuff/features/deeplabv2_vgg16/model120kimages/val/fc8/
# Evaluate performance
python models/deeplab/evaluate_performance.py
The table below summarizes the files used in these instructions:
| Filename | Description | Size |
|---|---|---|
| deeplabv2_vgg16_init.caffemodel | Deeplab VGG-16 pretrained model (original link) | 152 MB |
| deeplab_cocostuff_trainedmodel.zip | Deeplab VGG-16 trained on COCO-Stuff | 286 MB |
| deeplab_predictions_cocostuff_val2017.zip | Deeplab VGG-16 predictions on COCO-Stuff | 54 MB |
Note that the Deeplab predictions need to be rotated and cropped, as shown in this script.
Annotation Tool
For the Matlab annotation tool used to annotate the initial 10K images, please refer to this repository.
Misc
References
-
[1] COCO-Stuff: Thing and Stuff Classes in Context
H. Caesar, J. Uijlings, V. Ferrari,
In Computer Vision and Pattern Recognition (CVPR), 2018. -
[1b] COCO-Stuff: Thing and Stuff Classes in Context
H. Caesar, J. Uijlings, V. Ferrari,
In arXiv preprint arXiv:1612.03716, 2017. -
[2] Microsoft COCO: Common Objects in Context
T.-Y. Lin, M. Maire, S. Belongie et al.,
In European Conference in Computer Vision (ECCV), 2014. -
[3] Fully convolutional networks for semantic segmentation
J. Long, E. Shelhammer and T. Darrell,
In Computer Vision and Pattern Recognition (CVPR), 2015. -
[4] Semantic image segmentation with deep convolutional nets and fully connected CRFs
L.-C. Chen, G. Papandreou, I. Kokkinos et al.,
In International Conference on Learning Representations (ICLR), 2015. -
[5] LabelBank: Revisiting Global Perspectives for Semantic Segmentation
H. Hu, Z. Deng, G.-T. Zhou et al.
In arXiv preprint arXiv:1703.09891, 2017. -
[6] Scene Segmentation with DAG-Recurrent Neural Networks
B. Shuai, Z. Zuo, B. Wang
In IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2017. -
[7] Neuron-level Selective Context Aggregation for Scene Segmentation
Z. Wang, F. Gu, D. Lischinski, D. Cohen-Or, C. Tu, B. Chen
In arXiv preprint arXiv:1711.08278, 2017. -
[8] In-Place Activated BatchNorm for Memory-Optimized Training of DNNs
S. R. Bulò, L. Porzi, P. Kontschieder
In arXiv preprint arXiv:1712.02616, 2017. -
[9] Dynamic-structured Semantic Propagation Network
X. Liang, H. Zhou, E. Xing
In Computer Vision and Pattern Recognition (CVPR), 2018. -
[10] Context Contrasted Feature and Gated Multi-scale Aggregation for Scene Segmentation
H. Ding, X. Jiang, B. Shuai, A. Q. Liu, G. Wang
In Computer Vision and Pattern Recognition (CVPR), 2018.
Licensing
COCO-Stuff is a derivative work of the COCO dataset. The authors of COCO do not in any form endorse this work. Different licenses apply:
- COCO images: Flickr Terms of use
- COCO annotations: Creative Commons Attribution 4.0 License
- COCO-Stuff annotations & code: Creative Commons Attribution 4.0 License
Acknowledgements
This work is supported by the ERC Starting Grant VisCul. The annotations were done by the crowdsourcing startup Mighty AI, and financed by Mighty AI and the Common Visual Data Foundation.
Contact
If you have any questions regarding this dataset, please contact us at holger-at-it-caesar.com.

 46 Nov 17, 2022
46 Nov 17, 2022
 3 Mar 16, 2022
3 Mar 16, 2022
 9 Nov 07, 2022
9 Nov 07, 2022
 137 Dec 13, 2022
137 Dec 13, 2022
 107 Dec 29, 2022
107 Dec 29, 2022
 32 Dec 26, 2022
32 Dec 26, 2022
 39 Aug 19, 2022
39 Aug 19, 2022
 2 Apr 14, 2022
2 Apr 14, 2022
 29 Oct 24, 2022
29 Oct 24, 2022
 62 Dec 22, 2022
62 Dec 22, 2022
 1.8k Jan 07, 2023
1.8k Jan 07, 2023
 58 Dec 31, 2022
58 Dec 31, 2022
 50 Dec 07, 2022
50 Dec 07, 2022
 2 Oct 18, 2022
2 Oct 18, 2022
 19 Dec 12, 2022
19 Dec 12, 2022
 2 Dec 14, 2022
2 Dec 14, 2022
 5.6k Jan 04, 2023
5.6k Jan 04, 2023
 18 Nov 20, 2022
18 Nov 20, 2022
 2 Dec 30, 2021
2 Dec 30, 2021
 58 Nov 22, 2022
58 Nov 22, 2022