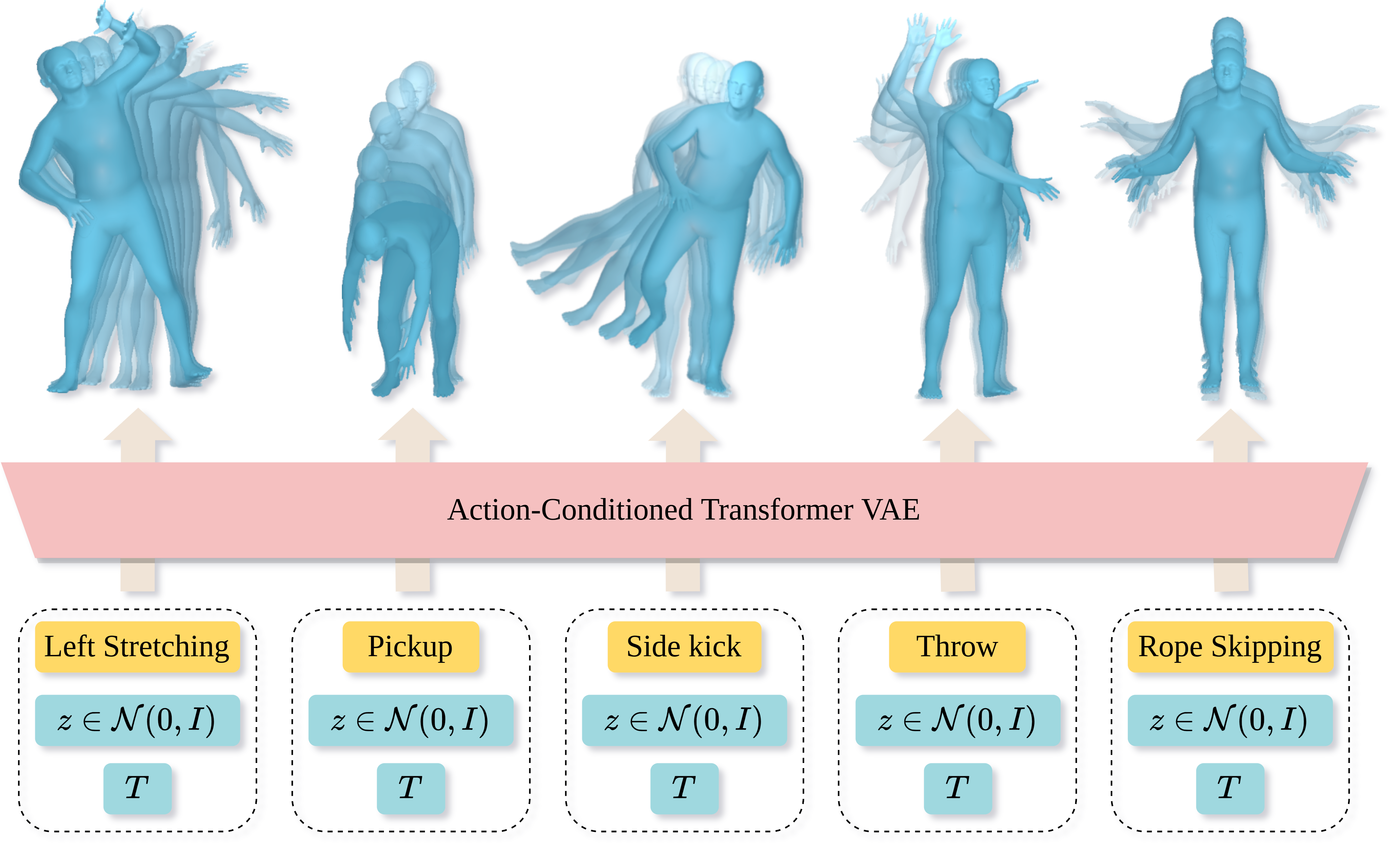
ACTOR
Official Pytorch implementation of the paper "Action-Conditioned 3D Human Motion Synthesis with Transformer VAE", ICCV 2021.
Please visit our webpage for more details.
Bibtex
If you find this code useful in your research, please cite:
@INPROCEEDINGS{petrovich21actor,
title = {Action-Conditioned 3{D} Human Motion Synthesis with Transformer {VAE}},
author = {Petrovich, Mathis and Black, Michael J. and Varol, G{\"u}l},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}
Installation
👷
1. Create conda environment
conda env create -f environment.yml
conda activate actor
Or install the following packages in your pytorch environnement:
pip install tensorboard
pip install matplotlib
pip install ipdb
pip install sklearn
pip install pandas
pip install tqdm
pip install imageio
pip install pyyaml
pip install smplx
pip install chumpy
The code was tested on Python 3.8 and PyTorch 1.7.1.
2. Download the datasets
For all the datasets, be sure to read and follow their license agreements, and cite them accordingly.
For more information about the datasets we use in this research, please check this page, where we provide information on how we obtain/process the datasets and their citations. Please cite the original references for each of the datasets as indicated.
Please install gdown to download directly from Google Drive and then:
bash prepare/download_datasets.sh
Update: Unfortunately, the NTU13 dataset (derived from NTU) is no longer available.
3. Download some SMPL files
bash prepare/download_smpl_files.sh
This will download the SMPL neutral model from this github repo and additionnal files.
If you want to integrate the male and the female versions, you must:
- Download the models from the SMPL website
- Move them to
models/smpl - Change the
SMPL_MODEL_PATHvariable insrc/config.pyaccordingly.
4. Download the action recogition models
bash prepare/download_recognition_models.sh
Action recognition models are used to extract motion features for evaluation.
For NTU13 and HumanAct12, we use the action recognition models directly from Action2Motion project.
For the UESTC dataset, we train an action recognition model using STGCN, with this command line:
python -m src.train.train_stgcn --dataset uestc --extraction_method vibe --pose_rep rot6d --num_epochs 100 --snapshot 50 --batch_size 64 --lr 0.0001 --num_frames 60 --view all --sampling conseq --sampling_step 1 --glob --no-translation --folder recognition_training
How to use ACTOR
🚀
NTU13
Training
python -m src.train.train_cvae --modelname cvae_transformer_rc_rcxyz_kl --pose_rep rot6d --lambda_kl 1e-5 --jointstype vertices --batch_size 20 --num_frames 60 --num_layers 8 --lr 0.0001 --glob --translation --no-vertstrans --dataset DATASET --num_epochs 2000 --snapshot 100 --folder exp/ntu13
HumanAct12
Training
python -m src.train.train_cvae --modelname cvae_transformer_rc_rcxyz_kl --pose_rep rot6d --lambda_kl 1e-5 --jointstype vertices --batch_size 20 --num_frames 60 --num_layers 8 --lr 0.0001 --glob --translation --no-vertstrans --dataset humanact12 --num_epochs 5000 --snapshot 100 --folder exps/humanact12
UESTC
Training
python -m src.train.train_cvae --modelname cvae_transformer_rc_rcxyz_kl --pose_rep rot6d --lambda_kl 1e-5 --jointstype vertices --batch_size 20 --num_frames 60 --num_layers 8 --lr 0.0001 --glob --translation --no-vertstrans --dataset uestc --num_epochs 1000 --snapshot 100 --folder exps/uestc
Evaluation
python -m src.evaluate.evaluate_cvae PATH/TO/checkpoint_XXXX.pth.tar --batch_size 64 --niter 20
This script will evaluate the trained model, on the epoch XXXX, with 20 different seeds, and put all the results in PATH/TO/evaluation_metrics_XXXX_all.yaml.
If you want to get a table with mean and interval, you can use this script:
python -m src.evaluate.tables.easy_table PATH/TO/evaluation_metrics_XXXX_all.yaml
Pretrained models
You can download pretrained models with this script:
bash prepare/download_pretrained_models.sh
Visualization
Grid of stick figures
python -m src.visualize.visualize_checkpoint PATH/TO/CHECKPOINT.tar --num_actions_to_sample 5 --num_samples_per_action 5
Each line corresponds to an action. The first column on the right represents a movement of the dataset, and the second column represents the reconstruction of the movement (via encoding/decoding). All other columns on the left are generations with random noise.
Example

Generating and rendering SMPL meshes
Additional dependencies
pip install trimesh
pip install pyrender
pip install imageio-ffmpeg
Generate motions
python -m src.generate.generate_sequences PATH/TO/CHECKPOINT.tar --num_samples_per_action 10 --cpu
It will generate 10 samples per action, and store them in PATH/TO/generation.npy.
Render motions
python -m src.render.rendermotion PATH/TO/generation.npy
It will render the sequences into this folder PATH/TO/generation/.
Examples
| Pickup | Raising arms | High knee running | Bending torso | Knee raising |
|---|---|---|---|---|
 |
 |
 |
 |
 |
Overview of the available models
List of models
| modeltype | architecture | losses |
|---|---|---|
| cvae | fc | rc |
| gru | rcxyz | |
| transformer | kl |
Construct a model
Follow this: {modeltype}_{architecture} + "_".join(*losses)
For example for the cvae model with Transformer encoder/decoder and with rc, rcxyz and kl loss, you can use: --modelname cvae_transformer_rc_rcxyz_kl.
License
This code is distributed under an MIT LICENSE.
Note that our code depends on other libraries, including SMPL, SMPL-X, PyTorch3D, and uses datasets which each have their own respective licenses that must also be followed.

 68 Dec 29, 2022
68 Dec 29, 2022
 8 Apr 25, 2022
8 Apr 25, 2022
 2 Feb 18, 2022
2 Feb 18, 2022
 147 Nov 18, 2022
147 Nov 18, 2022
 460 Jan 05, 2023
460 Jan 05, 2023
 76 Dec 20, 2022
76 Dec 20, 2022
 13 Jun 24, 2022
13 Jun 24, 2022
 2 Jul 01, 2022
2 Jul 01, 2022
 616 Jan 08, 2023
616 Jan 08, 2023
 106 Jan 03, 2023
106 Jan 03, 2023
 150 Dec 14, 2022
150 Dec 14, 2022
 36 Dec 12, 2022
36 Dec 12, 2022
 28 Dec 16, 2022
28 Dec 16, 2022
 1 Mar 01, 2022
1 Mar 01, 2022
 6.6k Jan 05, 2023
6.6k Jan 05, 2023
 127 Dec 31, 2022
127 Dec 31, 2022
 323 Dec 20, 2022
323 Dec 20, 2022
 708 Dec 19, 2022
708 Dec 19, 2022
 95 Jan 04, 2023
95 Jan 04, 2023
 0 Nov 25, 2021
0 Nov 25, 2021