Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings
Trong bài viết này mình sẽ sử dụng pretrain model SimCSE_Vietnamese để cải thiện elastic search trong bài toán semantic search.
Mọi người có thể xem bài viết hướng dẫn đầy đủ tại đây.
Cài đặt:
git clone https://github.com/vovanphuc/elastic_simCSE.git
cd elastic_simCSE
pip install -r requirements.txt
Đánh index cho toàn bộ data
python3 index_elastic.py
Search keyword và so sánh giữa BM25 (elasticsearch thường) và simCSE:
streamlit run main.py
Kết quả tìm kiếm:
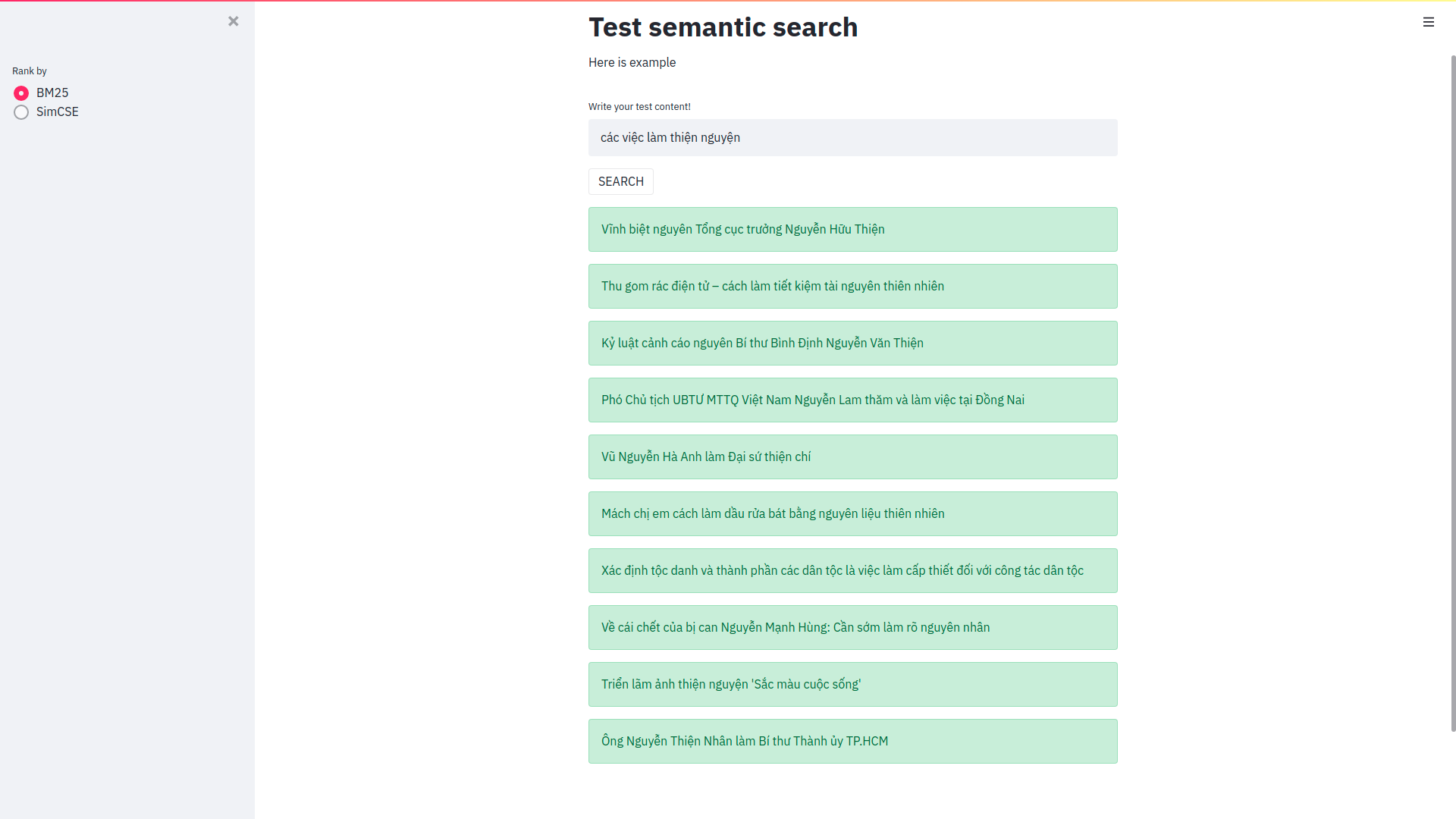
Kết quả khi sử dụng elasticsearch bình thường.
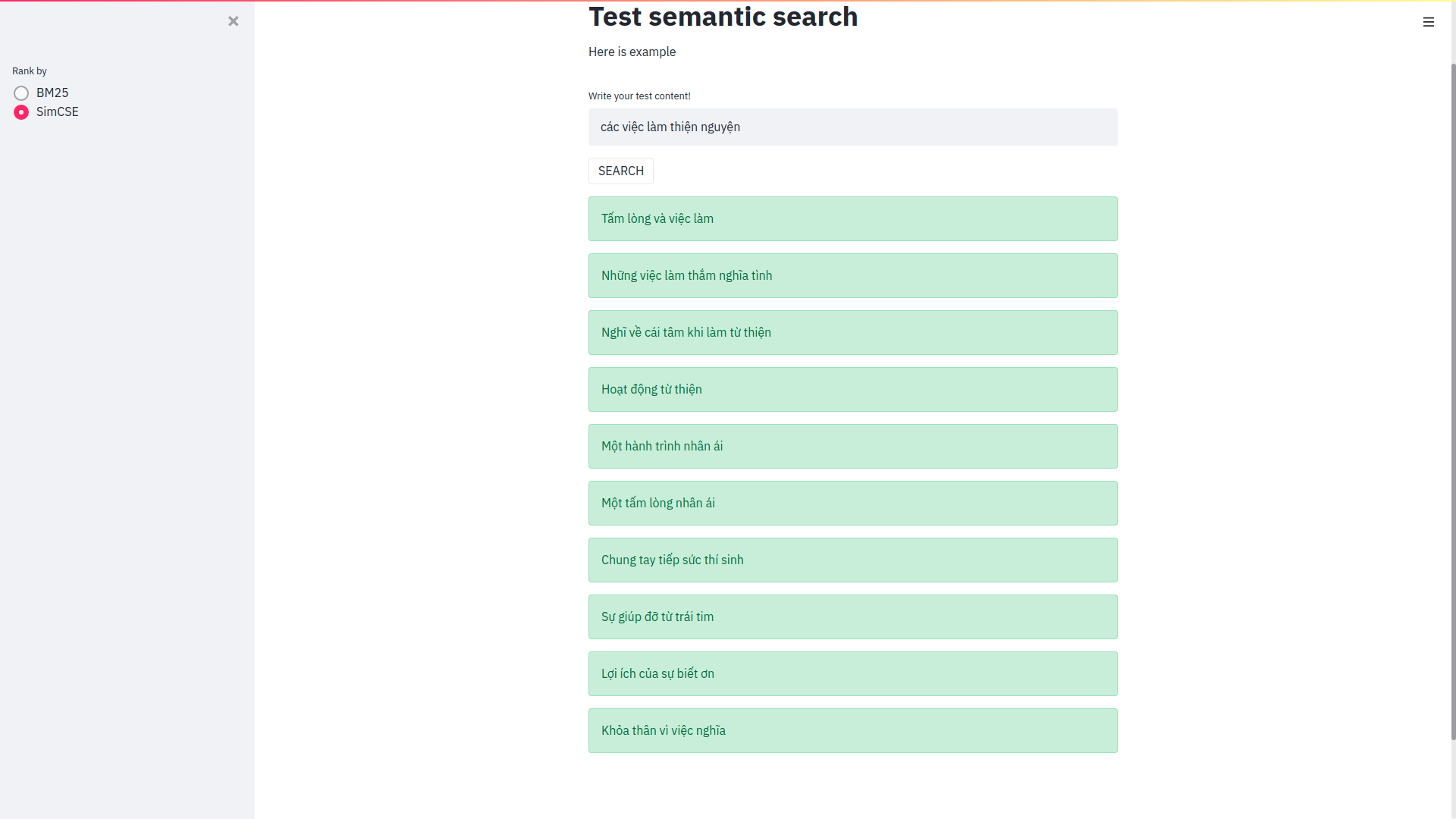
Kết quả khi sử dụng SimCSE_VietNamese.
Contact:
Email: [email protected]
Facebook: facebook.com/vovanphucc
Linkedin: linkedin.com/in/vovanphuc

 14 Dec 19, 2022
14 Dec 19, 2022
 135 Dec 29, 2022
135 Dec 29, 2022
 29 Nov 26, 2022
29 Nov 26, 2022
 3 Dec 02, 2022
3 Dec 02, 2022
 10 Jul 17, 2022
10 Jul 17, 2022
 83 Jan 09, 2023
83 Jan 09, 2023
 1 Nov 26, 2022
1 Nov 26, 2022
 4 Nov 24, 2021
4 Nov 24, 2021
 1.4k Dec 29, 2022
1.4k Dec 29, 2022
 3.8k Dec 30, 2022
3.8k Dec 30, 2022
 652 Jan 06, 2023
652 Jan 06, 2023
 217 Dec 05, 2022
217 Dec 05, 2022
 6 Nov 08, 2022
6 Nov 08, 2022
 2 Feb 22, 2022
2 Feb 22, 2022
 612 Jan 04, 2023
612 Jan 04, 2023
 7 Nov 09, 2022
7 Nov 09, 2022
 13 Nov 20, 2022
13 Nov 20, 2022
 224 Nov 29, 2022
224 Nov 29, 2022
 55 Nov 22, 2022
55 Nov 22, 2022
 2 May 12, 2022
2 May 12, 2022