VoiceFixer
Voicefixer aims at the restoration of human speech regardless how serious its degraded. It can handle noise, reveberation, low resolution (2kHz~44.1kHz) and clipping (0.1-1.0 threshold) effect within one model.
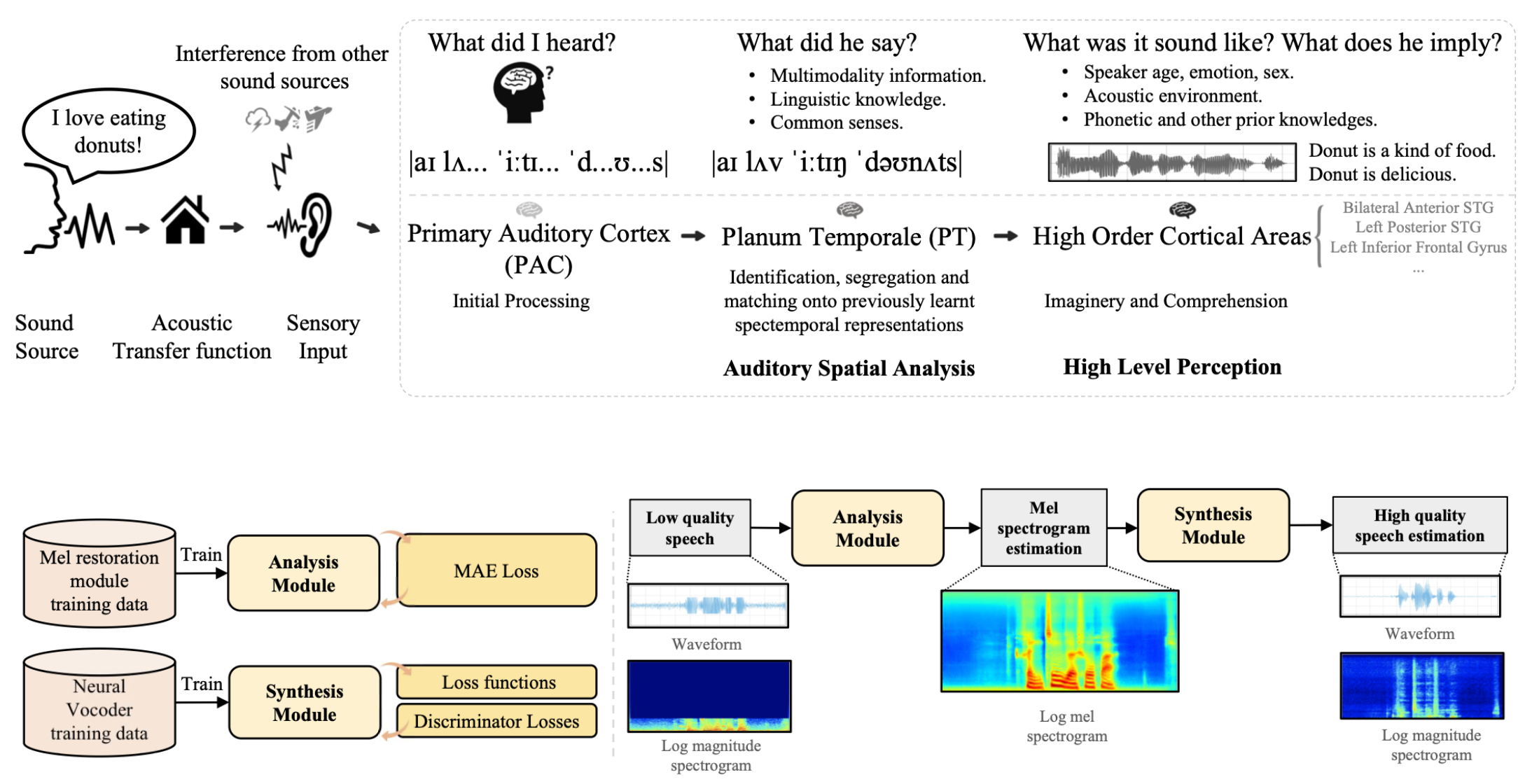
Demo
Please visit demo page to view what voicefixer can do.
Usage
from voicefixer import VoiceFixer
voicefixer = VoiceFixer()
voicefixer.restore(input="", # input wav file path
output="", # output wav file path
cuda=False, # whether to use gpu acceleration
mode = 0) # You can try out mode 0, 1 to find out the best result
from voicefixer import Vocoder
# Universal Speaker Independent Vocoder
vocoder = Vocoder(sample_rate=44100) # only support 44100 sample rate
vocoder.oracle(fpath="", # input wav file path
out_path="") # output wav file path
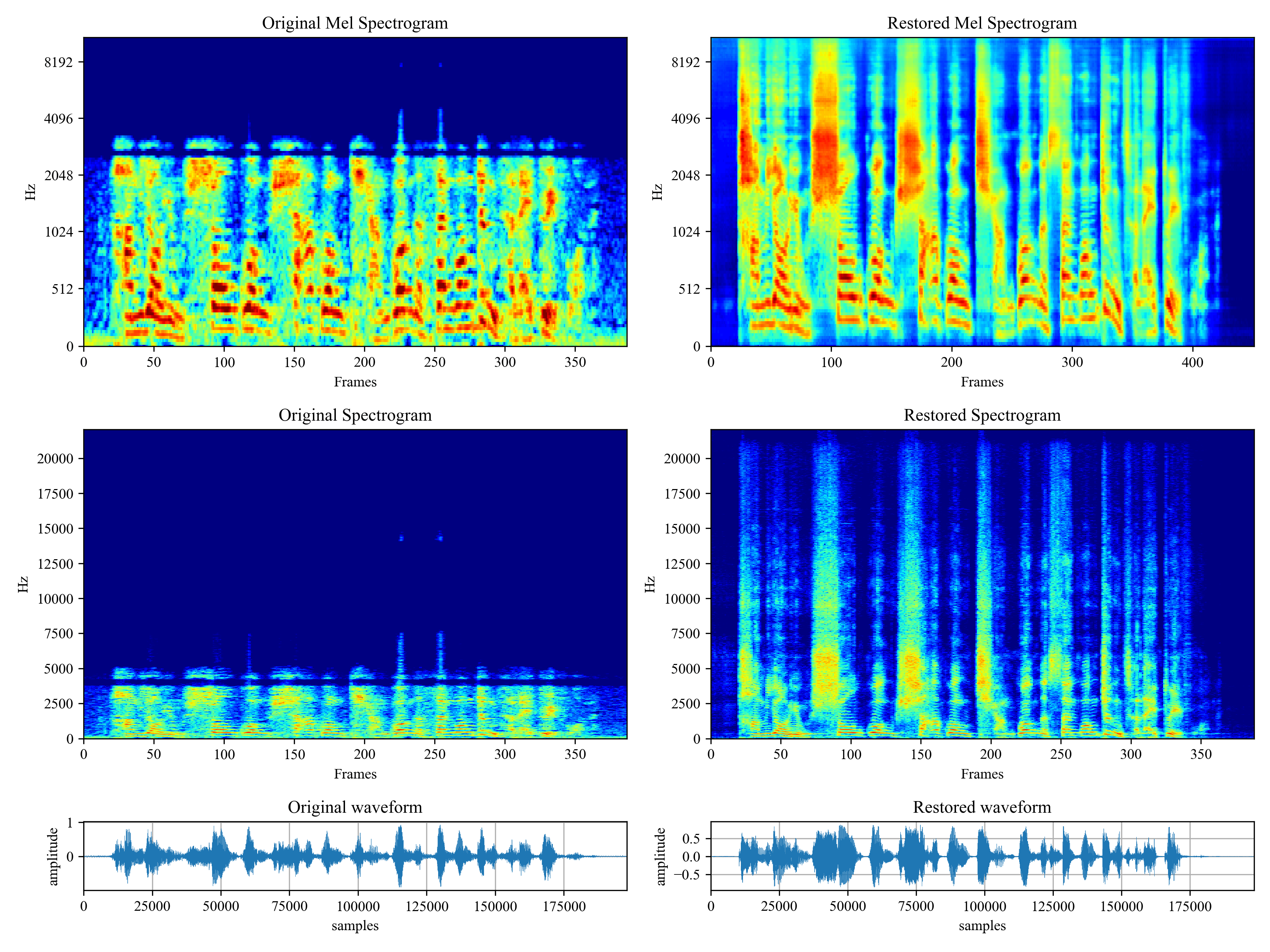
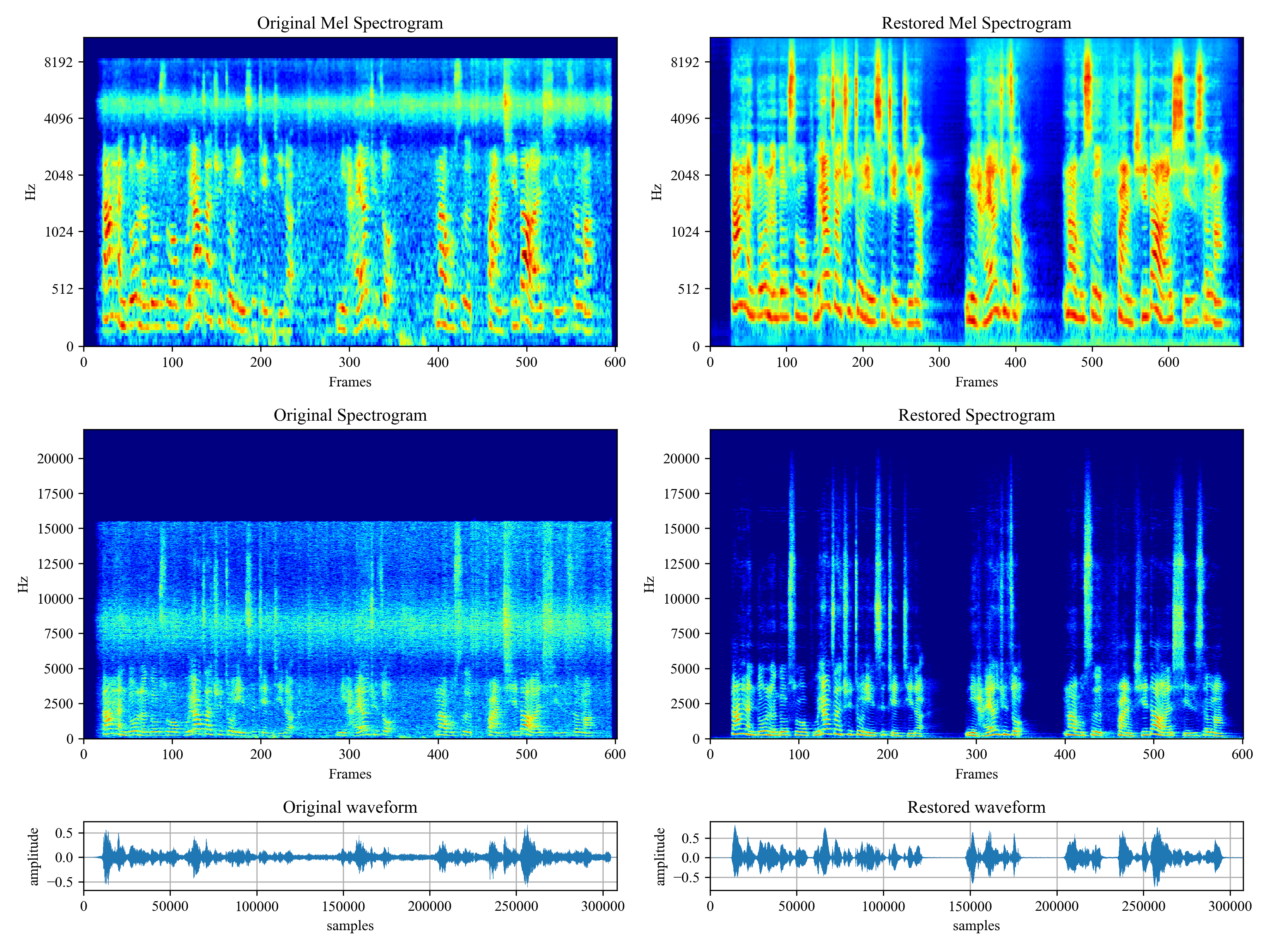
Related Material
- Paper: Will be available before Oct.03.2021.
- Train & Evaluation pipline (Still working on it): https://github.com/haoheliu/voicefixer_main






 Hi!
Hi!











 84 Dec 22, 2022
84 Dec 22, 2022
 78 Dec 31, 2022
78 Dec 31, 2022
 24 Sep 15, 2022
24 Sep 15, 2022
 19 Dec 01, 2022
19 Dec 01, 2022
 0 Nov 12, 2021
0 Nov 12, 2021
 425 Jan 01, 2023
425 Jan 01, 2023
 21 Jul 23, 2022
21 Jul 23, 2022
 3 Dec 28, 2022
3 Dec 28, 2022
 4 Dec 19, 2022
4 Dec 19, 2022
 111 Sep 21, 2021
111 Sep 21, 2021
 1.3k Jan 04, 2023
1.3k Jan 04, 2023
 1 Jan 24, 2022
1 Jan 24, 2022
 111 Jan 07, 2023
111 Jan 07, 2023
 1 Jun 28, 2022
1 Jun 28, 2022
 24 Dec 05, 2022
24 Dec 05, 2022
 844 Jan 07, 2023
844 Jan 07, 2023
 34 Jun 29, 2022
34 Jun 29, 2022
 13 Oct 21, 2022
13 Oct 21, 2022
 8 Aug 22, 2022
8 Aug 22, 2022
 2 Dec 15, 2021
2 Dec 15, 2021