序言
github上有很多好项目,但是国内用户连github却非常的慢.每次都要用插件或者其他工具来解决. 这次自己做一个小工具,输入github原地址后,就可以自动替换为代理地址,方便大家更快速的下载.
安装
pip install cit
主要功能与用法
主要功能
- change 将目标地址转换为加速后的地址
- clone 常见的git加速,最快10M/s,有时候慢一点
- sub git子模块加速,等同于git submodule add
- get 就是单纯的下载功能
示例用法
clone功能:等效于git clone <url>
cit clone <url>
# 示例
cit clone https://github.com/solider245/cit.git
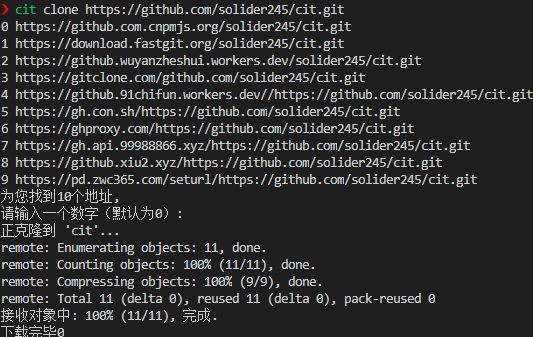
如上图所示,输入一个数字,选择一个链接即可开始下载.默认使用0.
sub功能: 等效于git submodule add <url>
cit sub <url>
# 案例
cit sub https://github.com/solider245/cit.git
逻辑和git clone一样,这里就不放图了.
get功能: 等效于wget下载 get功能会根据你的输入,智能判定下载raw文件或者release文件 使用示例:
cit get <url>
# 案例
cit get https://github.com/cheat/cheat/archive/4.2.0.zip
- 下载raw文件
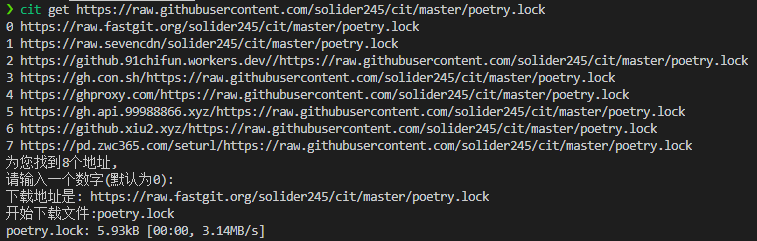

下载安装包.
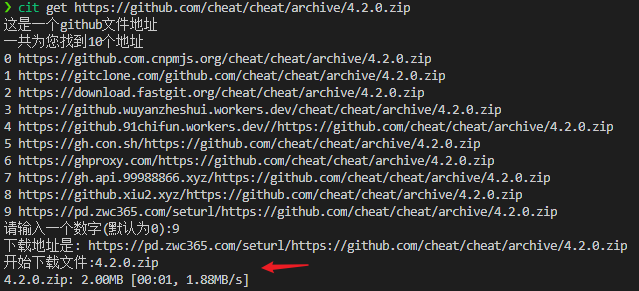
如上图所示,因为是使用https下载,所以速度快点惊人,如果下载速度太慢可以选择别的地址.我目前测试下来,基本都能用.
其他功能
- [x ] 常用软件下载,类似python,go等下载
- [x ] 常用系统加速,类似ubuntu或者centos等加速
- [] 其他常用功能
欢迎询问或者给我邮箱发邮件.

 2 Apr 26, 2022
2 Apr 26, 2022
 15 May 17, 2022
15 May 17, 2022
 45.5k Jan 07, 2023
45.5k Jan 07, 2023
 1 Jan 06, 2022
1 Jan 06, 2022
 1 Nov 26, 2021
1 Nov 26, 2021
 776 Jul 28, 2021
776 Jul 28, 2021
 1 Nov 10, 2021
1 Nov 10, 2021
 11 Dec 11, 2022
11 Dec 11, 2022
 3k Jan 04, 2023
3k Jan 04, 2023
 28 Oct 10, 2022
28 Oct 10, 2022
 0 Nov 07, 2022
0 Nov 07, 2022
 1.4k Dec 29, 2022
1.4k Dec 29, 2022
 0 Jul 04, 2021
0 Jul 04, 2021
 295 Dec 31, 2022
295 Dec 31, 2022
 5 Jun 23, 2022
5 Jun 23, 2022
 39 Dec 28, 2022
39 Dec 28, 2022
 0 Jan 07, 2022
0 Jan 07, 2022
 199 Dec 12, 2022
199 Dec 12, 2022
 0 Oct 10, 2021
0 Oct 10, 2021
 1 Sep 05, 2021
1 Sep 05, 2021