linkedin_webscraping
This is the first step of a full project called "LinkedIn Job Posting Analysis" and consists of a data ingestion (Extract and Load) procedure to retrieve information about jobs requirements in the data fields (Data Science, Data Engineering, Data Analysis, etc).
I started by navigating through the LinkedIn jobs page and searching for the desired job keyword using Selenium. After I found a good amount of jobs, I used the BeautifulSoup library to inspect the page and get, from each announced job, the full link for that post. This is our first function, get_links.
Then, looping through that list and using BeautifulSoup I was able to get the Job Title, Company Name, Job Location and Job Description for each job link. After some filtering on the Descriptions list, the data retrieved was put on a dictionary and turned into a Pandas DataFrame. This is our second function, jobs_dataframe, and it returns something like this:

Finally, after some small validation, the data is ready to be stored into a database. For this, I created a SQLite connection and a table using the sqlalchemy library to write SQL in Python. We can see the results in the picture below:
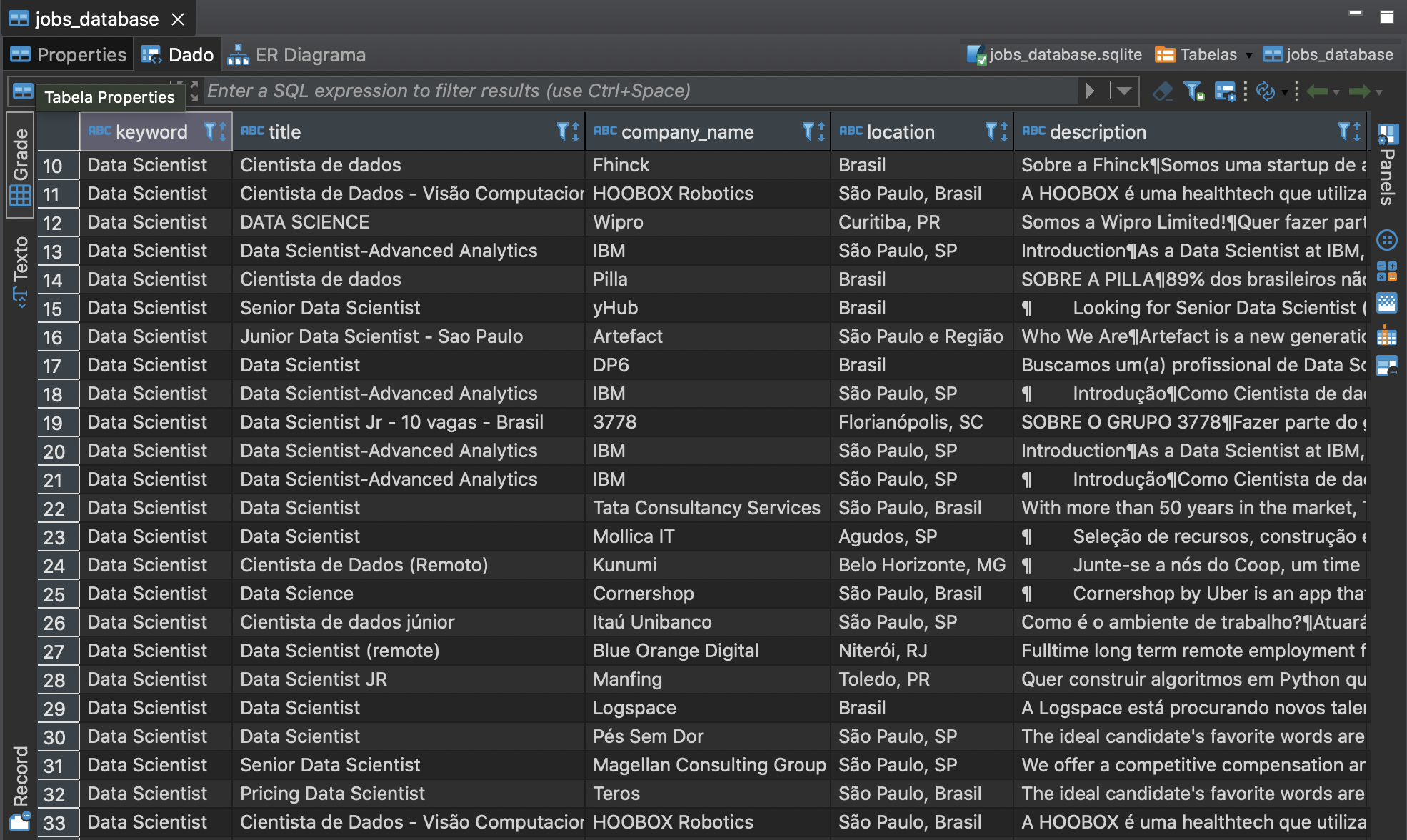
Despite we're already able to make some Data Analysis and maybe some Machine Learning using the data we have, I want to stress that this is an ongoing project for some reasons:
- First, I want to migrate these data from SQLite to a PostgreSQL database (so I can have more freedom to edit it) and create relational tables, using an efficient way to relate them;
- Second, maybe is it possible to refine a little bit more the description column and normalize all the table;
- Last but not least, this is just the first step of a bigger project, as I said earlier. So, we'll probably gonna make a lot of changes along the way, even though we may still use the EtLT pattern to do the engineering.
Dependencies
This project was made using Python 3.10.0
Executing
To run this project, in addition to Python, you'll need to have ChromeDriver and SQLite and its libraries for Python installed on your computer or on a virtual environment and chromedriver.exe on your project's folder. Then, run the linkedin_scraper.py file on your terminal window. Next, open the scraping_jobs notebook and substitute the keyword string of your interest on the job_keyword variable. Finally, run all cells and you're ready to open, on your database administration tool (mine's DBeaver), the data you've just got.
Author
Pedro Dib ([email protected])
Thanks
Thanks a lot to Igor Magalhães for the project idea, and for helping me with tips on writing good code and best practices on documentation.

 7 Oct 23, 2022
7 Oct 23, 2022
 10 Aug 18, 2022
10 Aug 18, 2022
 1.8k Mar 18, 2022
1.8k Mar 18, 2022
 1 Nov 13, 2021
1 Nov 13, 2021
 46 Dec 16, 2022
46 Dec 16, 2022
 1 Jan 28, 2022
1 Jan 28, 2022
 14 Dec 09, 2022
14 Dec 09, 2022
 1 Nov 10, 2021
1 Nov 10, 2021
 4.8k Jan 03, 2023
4.8k Jan 03, 2023
 2 Mar 12, 2022
2 Mar 12, 2022
 50 Jan 05, 2023
50 Jan 05, 2023
 87 Jan 06, 2023
87 Jan 06, 2023
 4 Sep 21, 2022
4 Sep 21, 2022
 2 Jan 24, 2022
2 Jan 24, 2022
 8 Oct 12, 2022
8 Oct 12, 2022
 1 Jan 31, 2022
1 Jan 31, 2022
 4 Aug 20, 2022
4 Aug 20, 2022
 185 Jul 23, 2022
185 Jul 23, 2022
 9 Nov 16, 2022
9 Nov 16, 2022
 13 Oct 15, 2022
13 Oct 15, 2022