JS-Secrets-Scraper
Python based Web Scraper which can discover javascript files and parse them for juicy information (API keys, IP's, Hidden Paths etc).
Screenshots
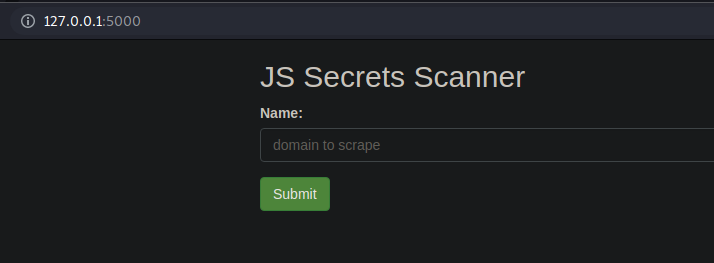
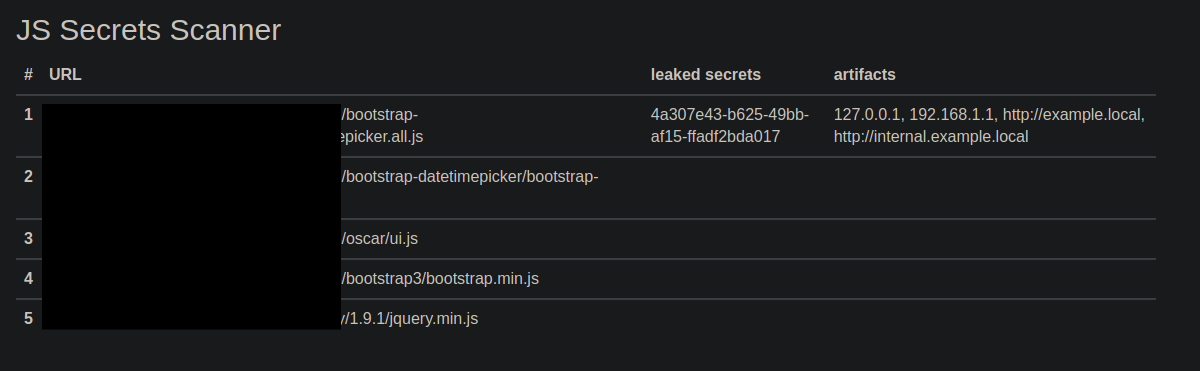
Technologies Used
- Flask
- Scrapy
Requirements
- Python 3
- Linux/Windows/MAC OSX
Installation
pip3 install -r requirements.txt
Usage
(+) usage: python3 ./web/main.py
Example
$ python3 ./web/main.py 2 ⨯
* Serving Flask app "main" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: on
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: XXX-XXX-XXX
Then, access the interface on http://127.0.0.1:5000/

 1 Feb 10, 2022
1 Feb 10, 2022
 1 Nov 13, 2021
1 Nov 13, 2021
 0 Nov 07, 2022
0 Nov 07, 2022
 2 Dec 22, 2021
2 Dec 22, 2021
 2 Apr 11, 2022
2 Apr 11, 2022
 73 Dec 03, 2022
73 Dec 03, 2022
 35 Nov 18, 2022
35 Nov 18, 2022
 33 Sep 03, 2022
33 Sep 03, 2022
 1 Jan 02, 2022
1 Jan 02, 2022
 53 Dec 21, 2022
53 Dec 21, 2022
 22 Nov 21, 2022
22 Nov 21, 2022
 4 Aug 20, 2022
4 Aug 20, 2022
 4 Dec 03, 2022
4 Dec 03, 2022
 1 Dec 15, 2022
1 Dec 15, 2022
 4 Dec 03, 2022
4 Dec 03, 2022
 68 Oct 08, 2022
68 Oct 08, 2022
 11 Nov 13, 2022
11 Nov 13, 2022
 6 Nov 21, 2022
6 Nov 21, 2022
 45 Dec 14, 2022
45 Dec 14, 2022
 3 Oct 04, 2022
3 Oct 04, 2022